
One of the main challenges large organizations face when it comes to data management is the lack of agility to respond quickly to market changes due to their bigger and more complex data structures. Lately, the data industry has found a solution to this challenge: Data Mesh and its 4 principles, including our topic today, domain-driven decentralized data ownership.
If you are not familiar with the framework, please feel free to take a look at our article on Data Mesh, where the concept is explained together with a quick snapshot of each of its principles.
Today, we’ll dive deep into one of them: domain-oriented decentralized data ownership.
The Problem: Central Data Teams Quickly Become a Bottleneck
Originally, many organizations had a central data team that was responsible for all changes that affect the data model (from data pipeline orchestration to building Machine Learning models).
The main problem with this approach is the lack of context for the team, which consequently implies more back and forth between business and data teams. Eventually, tasks start to pile up, producing a bottleneck for the whole organization that heavily relies on this central data team.
The Solution: Decentralization of Data and Its Ownership
What Data Mesh proposes is to follow the same approach that tech teams have been using for the past couple of decades. Embedding data team members into the business domain teams creates a decentralized structure that combines business, tech, and data skills in the same team.
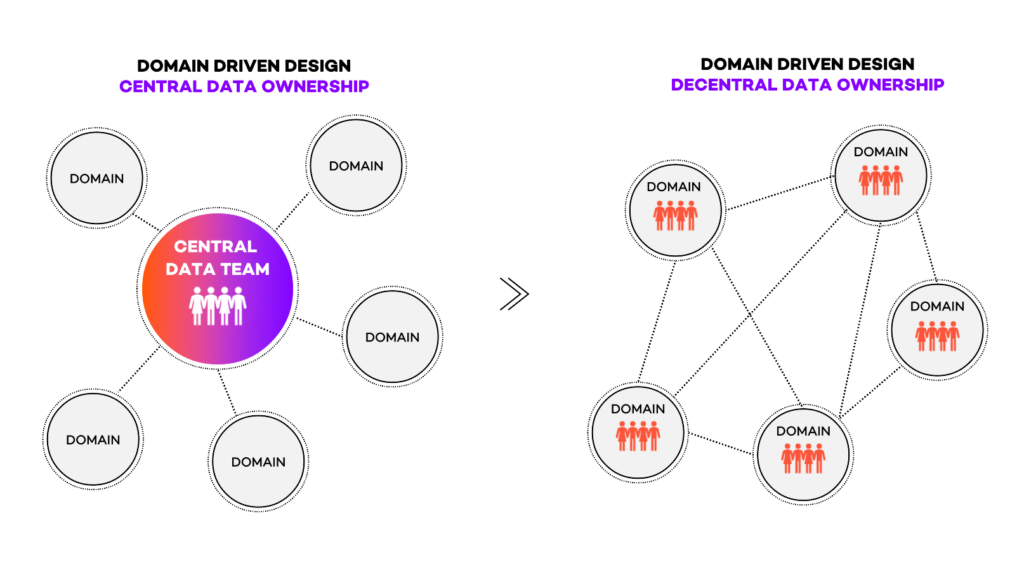
The immediate benefit of this is that now, data people would be the closest ones to the data that affects that particular business domain. This leads to more agility when it comes to decision-making and implementation because domain teams can work independently and autonomously on their domain-related data products and services.
What Is Domain-Driven Design (DDD)?
Zhamak Dehghani (who coined the term Data Mesh) based this principle of domain ownership on another similar (yet different) paradigm: domain-driven design. Domain-driven design (for short, DDD) was originally introduced by Eric Evans in 2003 in his famous book “Domain-Driven Design: Tackling Complexity in the Heart of Software”. It incorporates four main concepts:
1. Domain: A domain is a sphere of knowledge, influence, or activity.
2. Subdomain: A subdomain is similar to a domain but at a lower level, meaning a domain is usually composed of many subdomains.
3. Bounded Context: The concept of Bounded Context is linked to the concept of Ubiquitous Language, and it is a logical boundary that helps to define the scope of a Domain, while Ubiquitous Language highlights the need of having a well-defined vocabulary within this context where everyone understands every term or definition in the same way.
4. Context Mapping: Given that the same concept could have different names in different bounded contexts, we need Context Mapping at a higher level to avoid inconsistencies.
What Does Domain-Driven Design Look like in Real Life?
A typical example to explain and illustrate Domain-Driven Design are e-commerce companies. At an e-commerce company, there are usually very specific business domains (cross-functional teams that take care of a particular business capability end to end), such as: checkout, mobile, content, etc.
What Is the Domain Model in Domain-Driven Design?
A subdomain inside the checkout domain could be payments. Something important to mention is that there’s no clear definition for how to delimit a domain or subdomain.
Zhamak Dehghani proposes to take the current mental model as a starting point and iterate on it until an optimized structure is found. A second point to mention is that the domain model is not a static document, which means that it will evolve over time together with the market and the organization itself.
The Importance of a Common Language
Coming back to the Domain-Driven Design concepts, in this example, the bounded context would be the limit that defines the checkout domain, and ubiquitous language would be for example a glossary where all relevant definitions for that particular domain or context are described. As a result, the whole domain team would share a common vocabulary and understanding of domain-specific terms (e.g. everyone defines the conversion rate the same way).
Context Mapping in Domain Thinking
Finally, context mapping is the mapping between terms that belong to different domains. In this example, the e-commerce company might have the following domains: consumers and partners.
The consumers domain would focus on all the interaction with individuals who buy products through the website.
The partners domain would focus on the other side of the coin, meaning all the interaction with businesses that would sell their products. The team members of the partners domain would call these businesses customers, while the team members of the consumers domain might call them providers. Context mapping defines the relationship between these terms to avoid any misunderstanding in cross-domain communication.
My Experience with Domain-Oriented Data Ownership in Practice
From my experience, something very important to keep in mind at the time of running a DDD exercise is that there’ll be lots of discussions, and back and forth between the different stakeholders involved.
Complex topics include: the definition of domains and subdomains, what to build and what to buy, choosing the first domain as a pilot for the migration. My advice is to try to keep the process as lean as possible and to keep moving, otherwise progress will get blocked for months by just discussions.
Final considerations
As closing words, I’d like to mention that having seen first-hand how well data decentralization works, having data people integrated directly into the domain team or squad, I can only support this approach to allow businesses to get as agile as possible and to keep delivering fast.