
By now, it’s probably clear across the board that solid data management is the indispensable foundation for any company looking to expand or improve its use of AI. But what’s next? Once the basics are in place, data governance is up and running, and responsibilities are clearly defined, it’s worth taking a look at current developments. And yes, there are quite a lot of them. That’s exactly why we’re writing this article: so you only have to focus on the most relevant trends in the next few minutes.
*** Disclaimer: We don’t guarantee completeness, but we do promise a solid overview in 10 minutes.^^ ***
With a critical look at the intersections between data management and AI, we’ll walk you through 5 trends that are (or could be) driving digital transformation in organizations in 2026. At the same time, we’ll take a step back and revisit some of the data management trends we highlighted last year, analyzing how they’ve evolved since then.
Overview
- A New Leadership Setup: Chief Data Officer (CDO), Chief AI Officer (CAIO) and Governance-by-Design
- Data Provenance for More Trust in Data and Effective Metadata Management
- Productizing Data and Agent Experience (AX)
- DataOps 2.0: AI-native and with Conversational Data Access
- Real-time & Event-driven Data Management
If you’d like a quick refresher first:
“Data management is an organization’s practice of collecting, storing, processing and securing its data, with the objective of maximising the value of using data for all the different business processes.”
– Malina Iorga, Senior Manager Growth Marketing at Diconium Romania in “5 Data Management Trends in 2025”
1. A New Leadership Setup: Chief Data Officer (CDO), Chief AI Officer (CAIO) and Governance-by-Design
The rise of the Chief Data Officer (CDO)
Let’s start with the very first trend; less of a sudden breakthrough and more of a gradual shift: the role of the Chief Data Officer, or CDO, has never been as present as it is this year. A recently conducted 2026 AI & Data Leadership Executive Benchmark Survey with cross-industry executives showed that back in its first run in 2012, only 12% of surveyed companies had appointed a Chief Data Officer – mostly in financial institutions. Over the years, the role has evolved, shifting its focus from purely risk and regulation toward business growth driven by the potential of data. It has moved from a rather defensive function to a more offensive, innovation-driven one. In many organizations, this has further developed into the role of Chief Data and Analytics Officer (CDAO). And today, in 2026? Around 90% of companies have appointed a CDO or CDAO.
The Chief AI Officer (CAIO): competition, coexistence, or “same same but different”?
At the same time, another leadership role is gaining traction across organizations: the Chief AI Officer, or CAIO. While this role barely existed a few years ago, around 38.5% of organizations now have a CAIO or a comparable position and the number is growing. In parallel, a clear trend is emerging: some companies are starting to combine data, analytics, and AI responsibilities into a single role. In organizations without a CAIO, responsibility for AI still often sits with the CDO. That might be a sign that these roles are more likely to merge in the mid-term rather than coexist long-term.
A few open thoughts to put these roles into perspective:
- If a company treats AI as an isolated technology, separating CDO and CAIO can make sense. In reality, though, AI fully depends on data quality, access, and governance, so combining the roles might make sense from a content perspective. Whether it works organizationally probably depends on the company.
- Shouldn’t a Chief AI Officer have at least the same depth of understanding when it comes to data architecture, data quality, and data ownership as a CDO? Without that foundation, AI remains strategically shallow or operationally risky.
- When roles are split, there’s a real risk of responsibility diffusion: who’s ultimately accountable for faulty models, unclear data lineage, or regulatory risks-the Chief of Data or AI?
- On the other hand, giving one role too much scope without the right mandate, budget, or organizational leverage can result in neither data nor AI being managed properly-a lose-lose situation
The need for Governance-by-Design
Data governance is the strategic top layer of data management. It builds on well-structured data and consistent data quality, taking a broader, long-term perspective. It defines how data can be used to create sustainable business value, for example, revenue growth through precise customer data or the development of innovative data products. But data governance only becomes truly actionable when there’s a solid data management foundation in place. Otherwise, it remains theory.
As data and AI responsibilities increasingly converge, adding a bit of governance on top is no longer enough. It needs to be embedded directly into structures, roles, and technical processes – also known as governance-by-design. Governance-by-design is a key topic when it comes to thoughtful organizational and leadership design. In practice, it means defining clear ownership for domains and data products, and setting explicit decision rights (who is allowed to approve, change, or deploy what). When implemented well, governance-by-design reduces the need for manual approvals, minimizes errors and inconsistencies, and speeds up decision-making because responsibilities are clearly defined from the start.
In practice, this shows up in things like automated quality checks within data pipelines, predefined approval workflows for data products, built-in compliance checks in every deployment, or self-service data catalogs that give teams clear ownership and access structures.
If you want to read more about the topic of self-service in the data context, I recommend checking out my colleague’s article: Data Democratization: Empowering All with Self-Service Analytics.
2. Data Provenance for More Trust in Data and Effective Metadata Management
What is data provenance?
Provenance basically means origin or source. In a data context, data provenance refers to documenting where data comes from and which transformations it has gone through. It provides insight into the authenticity of data: who created it, what changes were made, and by whom.
A simple way to think about data provenance is through a journalistic process: imagine we conduct and record an interview. We store the recording and document who conducted the interview, who was interviewed, as well as the date and time. To turn it into an article, we shorten the transcript, remove filler words, and mark every edit as an update so others can see that the document has been modified and no longer reflects the original wording. For the headline, we might pull out a short quote. Ideally, we also document the historical context – when and in what situation certain statements were made.
If this kind of documentation is missing, it quickly becomes unclear which information is trustworthy, what changes have been made, and how certain data or quotes even came to be. That can lead to errors, misunderstandings, or wrong decisions; issues that can show up in any data-driven process.
Why do we need data provenance?
- Ensures data accuracy and regulatory compliance
- Promotes transparent handling of data, strengthening trust within and in organizations
- Makes it easier to assess data quality for business applications
- Supports better decision-making for new products or AI models by making the underlying data more understandable
- Preserves data quality even during team changes or when people leave the company, keeping information consistent and reliable
How metadata management supports data provenance
Metadata management provides the structure and visibility needed to make data provenance possible in the first place. Good metadata management ensures that information about data origin, changes, ownership, and context is systematically captured, connected, and accessible. This makes processes traceable, helps identify errors faster, and enables more efficient use of data products.
For more transparent data origins: The Data Provenance Initiative
One particularly interesting development in this space is the Data Provenance Initiative, driven by AI researchers from around the world. They’ve joined forces to conduct large-scale audits of datasets used to train AI models. Specifically, they analyze widely used training datasets, such as text, video, and audio, in terms of origin, licensing, authorship, and usage rights. The initiative is building a transparent, publicly accessible “provenance” registry that makes it possible to trace where data comes from and whether it can be used legally and ethically. They also make datasets, audits, and tools publicly available so that model developers, researchers, and companies can make more informed decisions. Their goal is to improve transparency, accountability, and compliance in AI development by making it clear what data models are actually trained on.
Even though things have been a bit quieter around them in recent months, they’re definitely not going to be the only initiative moving in this direction.
Image source: screenshot of the Dataset Explorer – https://www.dataprovenance.org/data-provenance-explorer/dataset-explorer
3. Productizing Data and Agent Experience (AX)
Our third data management trend is all about thinking of data as a product and what that means in practice. Data is treated much like a classic software product, with:
- A clearly defined Product Owner
- A roadmap with goals, milestones, and launches
- A strong focus on user-centered development that addresses concrete, pre-identified needs (we’ll get to who these users actually are in a second)
- Defined quality standards that are continuously tested against
- An MVP that is tested early with future users and iteratively improved
At the same time, there’s no single, universally accepted definition of data products. There’s no one single source of truth. IBM, for example, distinguishes between Data Products and DaaP (Data as a Product): DaaP describes a holistic approach to delivering data as a market-ready product, including code, data, metadata, and infrastructure, like a customer insights platform that combines all of a retailer’s touchpoints into a 360° customer view. Data Products, on the other hand, build on this foundation to deliver specific, more refined solutions such as dashboards, predictive models, or chatbots, focusing on clearly defined use cases.
Why is it worth thinking of data as a product?
- A clearly defined use case makes it easier to select the right data. A product doesn’t have to serve dozens of goals at once – it can do one thing really well.
- Clear ownership ideally leads to better knowledge sharing and more transparency around existing data.
- User-centered design becomes more important. This can increase actual usage and help users reach their goals faster (e.g., a “Import into Power BI” button instead of just a SQL table).
- A defined product lifecycle (from discovery to decommissioning) helps structure processes and solve recurring issues systematically rather than ad hoc.
If we think of data as a product, one question naturally comes up: who are the users, and how do they access it? Alongside team members, customers, and other humans, AI agents are increasingly becoming important users. Let’s take a closer look at them:
AI agents: the new users of data products
Just a few days ago, I came across a pretty interesting blog post: “Why the Future of Data Platform Engineering is Agent Experience (AX)”. In it, Robert Sahlin argues that platforms should no longer be dev-first, but agent-first. AI agents are becoming primary users and require smooth, reliable access to data, without human detours.
“We assumed the end user would always be a human sitting at a desk, looking at a screen. My work over the last six months has forced me to rethink everything. The developer we are building for is no longer just a human. As we move deeper into 2026, it is clear that AI agents will do the heavy lifting in coding and system management. If we continue to build for human eyes only, we will inevitably become the bottleneck in our own systems.”
– Robert Sahlin in “Why the Future of Data Platform Engineering is Agent Experience (AX)”
Sahlin’s logic applies to data platforms and equally to data products themselves. A good data product in 2026 needs to be understandable not only for humans, but also for agents: structured, predictable, API-first. Some of his key principles include:
- Programmatic over visual: agents need machine-readable interfaces, not search UIs with buttons
- Structured schemas: documentation should be standardized and machine-readable. No long-form wikis, but strict APIs, tech specs, and metadata files that clearly define what a tool can and can’t do. An LLM should be able to “see” that at first glance.
- Standards for autonomous discoverability: so agents can independently find and use data products and tools across platforms
From Developer Experience (DX) to Agent Experience (AX)
This is where the user experience of AI agents, the Agent Experience (AX), becomes the logical next step in the productization of data. As Sahlin puts it: “Stop being designers of user journeys and start being architects of agentic protocols.” So does that mean moving away entirely from well-designed, human-friendly interfaces? Not really. As always: use case first. If a data product is primarily used by humans, an agent-first approach isn’t always the right move. But keeping AX in mind when building new data products definitely won’t hurt.
Bottom line: the core principle stays the same… start with the user and their needs. Whether that user is a human or an agent.
Where innovation takes shape: Diconium’s Data Product Factory
At Diconium, data products are also playing an increasingly important role. The Data Product Factory is our experimentation space, where tomorrow’s data products are built. Here, some of the most creative minds in our team turn innovative ideas into market-ready solutions through a tailored program where our enabler team works side by side with data scientists, data engineers, AI experts, and legal specialists.
How did this come about? Diconium’s different locations have long been a melting pot of diverse backgrounds. In that environment, new ideas for data products are constantly emerging – some of which evolve directly into follow-up client projects. One particularly promising idea was too raw for direct client work, so it was developed “on the side” within the factory. After multiple iterations, it turned into a robust framework for successfully launching data products.
Alongside the creative space, the factory offers a structured 4-phase program (Exploration → Design → Implementation → Launch), based on learnings from past projects and proven lean startup methods. And that’s how spontaneous inspiration turns into a real, usable product. You can read more about it on our Data Product Factory landing page.
Image source: https://applydata.io/customer-lifetime-value/
Data Fabric makes data products possible
A year ago, we were still celebrating data fabric as a standalone megatrend: the technology that breaks down silos and stitches together data from all corners into one seamless puzzle.
“Data fabric is a term that is used to describe a data management architecture that is designed to provide a seamless and consistent way to access and manage data from various sources, including on-premises systems, cloud-based systems, and other types of data stores. A data fabric typically includes a set of tools and technologies that enable data integration, data management, and data governance across an organization’s entire data ecosystem.
The goal of a data fabric is to make it easier for organizations to access and use their data in order to gain insights, make better decisions, and improve business outcomes.”
– Malina Iorga, Senior Manager Growth Marketing at Diconium Romania in “5 Datenmanagement Trends in 2025”
So what happened in 2026? Data fabric hasn’t disappeared, but has proven itself as the technical backbone that makes data products possible in the first place. Data product teams no longer have to deal with integration chaos and can instead focus on user needs or AX. Fabric runs quietly in the background, keeping data accessible while products take shape in the foreground.
4. DataOps 2.0: AI-native and with Conversational Data Access
“DataOps is a set of practices within a collaborative data management model, which aims to bridge the gap between domain data owners and data consumers. To ensure the delivery of value from data, organizations need to accelerate the use of analytics and to empower data-driven decision-making.
Following in the footsteps of methodologies such as DevOps and DevSecOps, DataOps teams come together to accelerate the velocity of analytics in the company, translating it into actionable business intelligence. The methodology of DevOps is extended with data specialists such as data engineers, and data scientists. The goal is to enable data streams and the ongoing use of data across the enterprise.”
– Malina Iorga, Senior Manager Growth Marketing at Diconium Romania in “5 Datenmanagement Trends in 2026”
In last year’s article “5 Data Management Trends in 2025”, we listed the “rise of DataOps” and “automation and AI” as two separate trends. This year, they’re back again but merged, because they clearly belong together.
DataOps bridges the gap between domain data owners and users by applying DevOps practices to data pipelines: continuous integration, testing, and deployment for analytics that accelerate data-driven decision-making. And DataOps 2.0 is AI-native: machine learning is embedded directly into pipelines and becomes a core part of the architecture. … What AI-native actually means? Think of pipelines that automatically detect data changes (drift) before queries even fail, for example, when customer behavior shifts or data sources introduce new formats. AI monitors metrics, retrains models autonomously, and resolves anomalies on its own.
Conversational data access makes data self-service easier
Sometimes, talking is just faster than typing. Since last year, more and more companies have been offering voice-based AI assistants (often referred to as conversational AI), such as data analysis assistants to interpret and contextualize existing big data, or as integrated tools for fast and easy data access. NLP (Natural Language Processing) interfaces support the democratization of data and improve accessibility, for example, for people with writing difficulties or hearing impairments. Natural language makes data accessible and tangible for all teams, without the need to learn query syntax or undergo BI tool training.
Conversational AI in data analysis
You could, for example, ask: “Show me Q1 2026 revenue by region, including a forecast and top-selling products.” Conversational AI is built on LLMs and understands not just words, but also context, nuance, and intent. If you follow up with something like “What if we reduce prices by 5%?”, you can quickly get answers to your most important questions. Especially when working with large datasets, AI can be a strong support. That said, your own critical thinking still matters, and too vague questions can lead to misinterpretations. Solid governance is also essential to clearly define security standards and data access.
Conversational AI agents are also increasingly being used in online shops, transforming traditional e-commerce into AI-driven commerce. If you want to dive deeper into this, check out: What is Conversational AI and how can it support online shop owners?
5. Real-time & Event-driven Data Management
We’ve already reached the final trend for 2026: real-time and event-driven data management. But what does that actually mean? Data is no longer processed in batches (i.e., uploaded offline in large chunks every few hours or days), but handled live. Triggered by events such as customer actions (e.g., cart abandonment), sensor signals, or market changes, systems react instantly.
Why does this matter now? Customers have gotten used to real-time personalization, supply chains need disruption alerts, and agents rely on live data to make autonomous, dynamic decisions.
Event streaming for fast live data processing
At the core is event streaming, powered by technologies like Apache Kafka or Apache Flink. Kafka transports events (= messages/information) quickly from A to B and ensures nothing gets lost. Flink builds on top of that and processes the data instantly, without everything needing to land in a central cloud first. And according to a market analysis by Mordor Intelligence, the global event stream processing market is steadily growing: from $1.41B in 2025 to $1.61B in 2026, and expected to reach $2.94B by 2030.
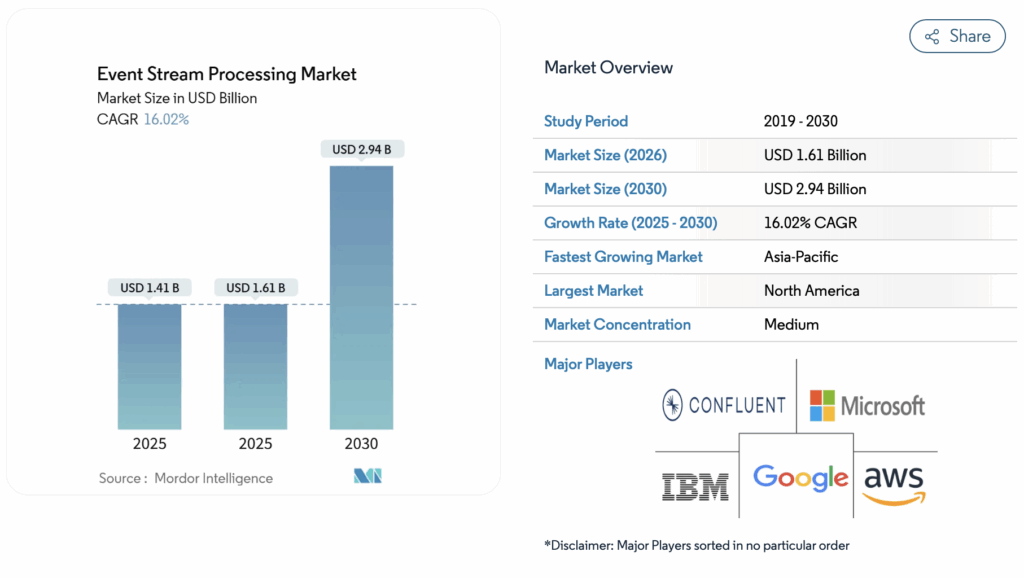
Image source: Mordor Intelligence Research & Advisory. (2026 , February). Event Stream Processing Market Size & Share Analysis – Growth Trends and Forecast (2026 – 2031). Mordor Intelligence. Retrieved May 5, 2026, from https://www.mordorintelligence.com/industry-reports/event-stream-processing-market
Yingjun Wu, Founder & CEO of RisingWave, shared deeper insights into event streaming at our Berlin applydata meetup. In his keynote “Achieving Sub-100ms Real-Time Stream Processing with an S3-Native Architecture”, he explained how to reach latencies below 100 ms with these kinds of systems.
Edge Analytics: from trend to foundation for real-time & event-driven data
In 2025, we also highlighted edge analytics as a trend, because more and more connected devices and vehicles needed to process data directly at the source. Think of vehicles analyzing charging processes and sensor data locally, or machines detecting anomalies directly on the production line.
Edge analytics refers to the initial processing of data on or near devices (e.g., onboard computers in cars, IoT devices), instead of sending all raw data unfiltered to the cloud. This saves bandwidth, reduces latency, and helps meet data privacy requirements, especially in industries like automotive or healthcare.
From today’s perspective, edge analytics is less of a standalone trend and more of a foundational building block within the broader real-time and event-driven data management landscape. Events such as sensor data or user interactions are pre-processed or evaluated at the edge and then passed into streaming systems. This allows devices to detect events almost instantly, make initial decisions locally, and forward only relevant events into central streaming architectures.
Edge analytics at Diconium
“In our long-standing history within the mobility sector, we have tapped into edge analytics for several projects, two of which we like to think stand out as particularly bold:
Car data
Working with a German car manufacturer during the months leading up to the release of their e-car model, our colleagues developed an app which integrates seamlessly with charging stations. The solution allows car owners to access charging services data from the edge and plan their trips in advance with full predictability regarding providers, locations, connections, and more.
Monetization of data
For the second project, we partnered up with a B2B automotive company which collects tremendous amounts of sensor data points. Our mission was to gauge the financial potential of their data assets, which brings us to a critical point when discussing data capital – monetization. Because all businesses are in the money business, edge analytics can provide valuable monetization sources for companies looking to diversify their revenue streams.”
– Malina Iorga, Senior Manager Growth Marketing bei Diconium Romania in “5 Datenmanagement Trends in 2025”
Summary of Our 5 Data Management Trends in 2026
We’ve walked you through our five data management trends for 2026: the growing importance of roles like Chief Data Officer and Chief AI Officer, data provenance for increased trust in data, the productization of data with a focus on Agent Experience (AX), AI-native DataOps 2.0 with conversational data access, and real-time, event-driven data management. As everything continues to evolve faster and faster, the risk of losing focus grows. The key is to pick the trends that actually create value for your business.
So… what trends are missing on our list? And which of these do you think will still matter in 2027?
Author info
