
In this part of our series about Data Mesh and related topics, I would like to dig a bit deeper into the so-called self-serve data infrastructure principle. While domain-driven design and applied product thinking are widely known and adopted concepts, the principle and application of a self-serve data infrastructure seems a bit harder to grasp based on conversations I had recently.
Self-serve data infrastructure seen through the abstraction lens
As previously expressed in our cornerstone article on Data Mesh, central data teams are often a bottleneck for efficient data usage, and the self-serve data infrastructure principle – among other things – aims to change that. But how?
One of the basic underlying principles of a self-serve data infrastructure is abstraction. Why abstraction? Abstraction is a classic software engineering principle and a specialization of the separation of concerns principle defined as “… a recognition of the need for human beings to work within a limited context”. Software engineers as well as data engineers, data scientists and data product owners alike are (still) human beings, and every organization that aims to improve time to market for data products should aim to reduce the context for people creating these values.
Abstraction can be useful in a plethora of contexts. Similar to what happened in line with the rise of microservice architectures (think Docker, K8s as abstractions of operating systems), abstraction could speed up and at the same time help scale data value creation tremendously, and there’s more than one reason why that is likely to be needed and will happen.
It’s not a secret that the amount of data is constantly growing, and many projections claim it will grow exponentially. And there’s more growth to be expected. Based on a yearly review done by Matt Turck, an almost exponential increase in data, AI and ML related solutions happened between 2012 and 2023. While in 2012 it would have been still possible to know or master a good number of tools and technologies, I doubt that in 2023 it’s still possible (or useful) for one person to do that.
Imagine if every car manufacturer had, over time, defined their own proprietary interfaces to interact with a car for controlling direction and speed. Instead of steering wheels there would be handlebars, joysticks, touchpads, switches, shifters, pedals, etc. You wouldn’t have to get one driving license, but a new one every time you want to drive a different car.
Affordances in a data environment
With more and more (specialized) solutions and a growing amount of data it will most likely not become easier to find enough of and the right specialists to make efficient use of data – unless we find a way to speed up the value creation process and optimize for scale.
Following the principle of abstraction, the self-serve data infrastructure and the multiplane approach with a mesh experience plane, data product experience plane and data infrastructure (utility) plane suggests common necessary affordances (actions possible) in a data environment.
More concretely, this means to apply product thinking to use cases for data product creators and users. As shown in fig. 1, a data product owner or data governance expert, might want to search for existing data products, and could do so on a mesh experience level.
The results shown in that search could have been automatically added to the search when the data product team created the data product, using an underlying indexing functionality, provided by a data platform product team.
The different plane’s experiences accommodate the user experience requirements of the previous abstraction level. The data platform team builds the indexing functionality according to the data product team’s needs, and the data product team uses provided affordances to allow the mesh experience plane to provide search results as per the need of the users of the plane.
Most affordances will be built incrementally, starting with the most relevant ones first, and building on top of each other. The different planes won’t necessarily exist in a defined form – it will depend on the users using the plane functionality.
That means, a more technical user group of the mesh level, would maybe be fine to use SQL for searching. A less technical user group and more mature data mesh infrastructure might provide a web interface with a full text search.
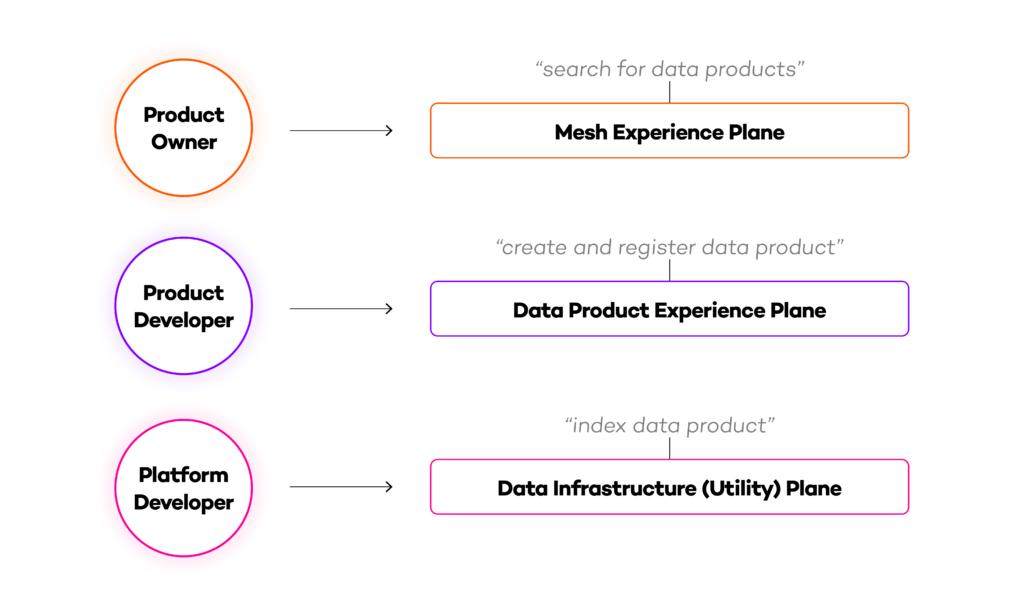
The growing number of features allows more generalist product teams to build and use data products fast, by using standardized abstractions for e.g., searching, monitoring, controlling, transforming, registering or deploying data products on different abstraction levels (planes) without knowing about underlying implementations.
Closing considerations on using a self-serve data infrastructure in a Data Mesh
Providing a self-serve data infrastructure not only removes the need for specialist knowledge about how e.g., the search is implemented, how monitoring is supported and integrated or a data product is registered in a domain team, but in consequence also reduces the effort needed to build data products and therefore speeds up the process and increases quality through standardization.