
When we talk about the LLMs, two primary things came together and allowed us to experience these awesome models. The first idea was the Transformer; the second idea was unsupervised pre-training. Combining these innovations allowed us to almost magically produce results on downstream tasks that we weren’t expecting.
How GPT Is Trained
If we look specifically at how GPT is trained, it uses two training techniques: unsupervised pre-training with the Transformer on very large data and supervised fine-tuning. It also required specific adaptations to the architecture. Even without task-specific modifications, we started to see some amazing results come together.
So let’s understand on unsupervised pre-training.
What Is Unsupervised Pre-training in LLM?
We might lose ourselves if we think too rigidly in terms of binary supervised or unsupervised learning as we get into LLM. Unsupervised pre-training is built on the back of a technique called semi-supervised sequence learning, which combines unsupervised and supervised learning. While we call it unsupervised, in fact, it’s leveraging a semi-supervised approach.
Pre-training in LLMs refers to training a transformer-based model on large amounts of mostly unlabelled text using a next-token prediction objective. Although often called “unsupervised,” it is better described as semi-supervised sequence learning, where the model learns general language representations that can later be adapted to downstream tasks through fine-tuning.
Fine-tuning is the process of updating a pre-trained LLM’s weights using a task-specific supervised dataset. While pre-trained models can perform many tasks through prompting, fine-tuning is used to improve performance, reliability, and alignment for specific use cases such as text generation, classification, summarization, or instruction following.
Labeling the Data
This improves document classification performance using an unsupervised pre-training approach of an LSTM (long short-term memory) network followed by supervised fine-tuning. Initially, unlabelled data was used, and the unsupervised prediction of what cames next allowed us to label the data. After this pre-training step, the recurrent neural network (the LSTM) became more stable and generalized better than any other approach we had used before.
By the way, if you want to read more about data labeling, especially in the automotive industry, feel free to check out my colleague’s article Data Labeling as a Continuous Service.
Introducing the ULMFiT-Paper
Another key idea emerged from a paper called the Universal Language Model Fine-Tuning for Text Classification (ULMFiT). This was when everyone was paying attention to computer vision and transfer learning. They proposed that a pre-trained model could be fine-tuned for state-of-the-art performance on various classification tasks. That means we can use some transfer learning techniques with natural language processing. We can do pre-training, followed by fine-tuning, to achieve excellent results in classification tasks.
We can use the idea of semi supervised sequence learning to perform unsupervised pre-training and then fine-tune the pre-trained model for state-of-the-art performance on many different classification tasks.
What Is Supervised Fine-tuning in LLM?
Once pre-trained with a large corpus of data, what the model does out of the box is predicting the next word autoregressively. That’s all it does. There are some tasks that make sense to perform with the pre-trained model that’s not fine-tuned, and there are some tasks that don’t. Regardless of whether the task you’re trying to perform with a pre-trained model out of the box makes sense, you could fine-tune a pre-trained model for that task.
Supervised fine-tuning is typically task-specific and could be for generative tasks. In the context of LLMs, we are talking about generative supervised fine-tuning, but we can also fine-tune for tasks that are not generative, like classification, similarity, or entailment. Pre-trained LLM models like GPT-2 and GPT-3 are performing better in generative tasks and other language tasks like question answering, summarization, and translation. They show better results without any fine-tuning, simply by prompting.
The Three Different Learning Methods
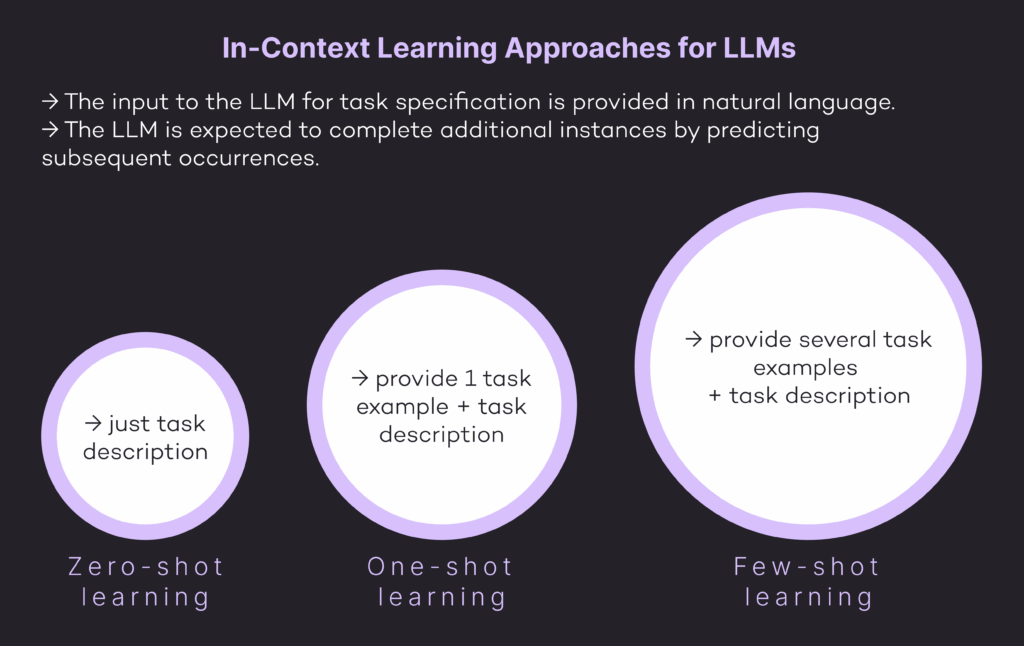
- Zero-shot learning: No task-specific data is needed; the model can predict the answer with only a natural language description of the task.
- One-shot learning: A single example of the task is provided in addition to the task description.
- Few-shot learning: A few examples of the task are provided with the task description.
All these zero, one, and few-shot learning methods are not considered fine-tuning because no gradient updates are performed. These are in-context learning approaches, where the input to LLM for task specification is in natural language with a few examples, and LLM is expected to complete further instances by predicting next occurrences.
In supervised fine-tuning, it updates pre-trained model weights by training on a supervised dataset, typically ranging from 1 to 100,000 examples specific to the particular task.
Instruction tuning
Instruction tuning is also a supervised fine-tuning approach but doesn’t require a much larger dataset. Instead of providing input and output data examples, it needs prompt and completion pairs demonstrating the expected behavior. Instruction tuning allows models to be adapted quickly with fewer examples, which is more efficient than the extensive datasets required for fine-tuning or the iterative feedback loops of RLHF. It relies heavily on prompt and completion examples, which can lead to inconsistencies and unpredictability if the prompt is not carefully crafted—a difficult task. Instruction fine-tuning trains the model using examples that show how it should respond to specific instructions.
Zero-shot, one-shot, and few-shot learning are in-context learning methods where the model adapts to a task using natural language instructions and examples in the prompt without updating model weights. Fine-tuning, in contrast, involves gradient updates to the model parameters using a supervised dataset and results in persistent changes to the model’s behavior.
What Is RLHF, RLAIF, DPO and Where Comes it into Place?
These three techniques are broadly used for further alignment of LLMs. Alignments in LLM mean making LLM behave in accordance with human preferences. LLM alignments can also be considered a fine-tuning approach used in the context of LLMs but not supervised fine-tuning.
RLHF
RLHF stands for Reinforcement Learning from Human Feedback, which is used for tasks where defining a clear, algorithmic solution is challenging. It has two main components: Reinforcement Learning (RL) and Human Feedback (HF).
Humans can easily evaluate the model’s output in this approach. When a polite response is expected from the model while avoiding biases, but clear rules are not available, RLHF is the best approach to address this issue. When we talk about LLM training, we only mean updating the parameters of the language model. However, when we use RLHF, we train the parameters of three separate models:
- LLM: pre-trained LLM which will be fine-tuned based on instruction data.
- Reward Model: trained on human feedback data to predict human preferences and provide reward signals to reinforce the policy model.
- Policy Model: uses reinforcement learning with the reward model as its source of feedback and will be trained to generate tokens by maximising the predicted reward.
The LLM’s weights are adjusted and fine-tuned in the Reinforcement Learning phase, where the model learns to optimise its actions to maximise rewards. RLHF improves LLMs to be more efficient and reliable by incorporating feedback from human evaluators, which also making them more truthful, helpful, and contextually relevant.
RLAIF
Reinforcement Learning from AI Feedback is a comparatively new technique that enables training reinforcement learning (RL) models without relying on human-labeled training data. Collecting human labels is expensive and time-consuming. RLAIF offers a path to circumvent this bottleneck by replacing human raters with an LLM labeller. RLAIF uses preferences generated by a large language model (LLM) to train the RL model. According to researchers, RLAIF can match the performance of traditional RLHF on text summarization tasks.
DPO
DPO stands for Direct Preference Optimization. Its aim is to align LLMs using a simpler, more memory-efficient algorithm than conventional alignment techniques pioneered by OpenAI and Anthropic. The basic idea is to change the optimization objective in a way that directly encodes or implicitly models the preferences a reward model would learn to represent. Therefore, instead of needing three models (SFT model, primary model, and reward model), DPO optimizes the original language model’s parameters more directly.
What Is PEFT and LoRA in Fine-tuning LLM?
The problem with training large language models and fine-tuning them is that we end up with really big weights. This raises several issues:
- A lot more compute is needed to train. As the models get larger and larger, you need much bigger GPUs and multiple GPUs just to fine-tune some of these models.
- The file sizes become huge. The large language models with billions of parameters are increasing in size all the time.
This is where the idea of Parameter Efficient Fine-Tuning (PEFT) comes in. PEFT uses various techniques. LoRA, which stands for Low-Rank Adaptation, originates from a paper focused on doing this for LLMs. Other techniques under PEFT include Prefix Tuning, P-tuning, and Prompt Tuning, which are not explained in this post.
The Topic of Catastrophic Forgetting
What PEFT does, particularly with LoRA, is allow you to fine-tune only a small number of extra weights in the model while freezing most of the parameters of the pre-trained network. The idea here is that we are not actually training the original weights. Instead, it adds some extra weights and fine-tunes those. One advantage of this is that the original weights are preserved, which helps prevent catastrophic forgetting. Catastrophic forgetting occurs when models forget what they were originally trained on during fine-tuning. If you fine-tune too much, the model may forget some of the original training data.
The Advantages of PEFT (Parameter Efficient Fine-Tuning)
PEFT doesn’t have this problem because it adds extra weights and tunes those while freezing the original ones. PEFT also allows effective fine-tuning with a small amount of data, and it generalizes better to other scenarios. Overall, it’s a huge win for fine-tuning large language models and even models like Stable Diffusion, which is starting to use this technique as well. One of the best aspects is that it results in just tiny checkpoints.
So, it’s tiny now and still needs the original weights. It’s not completely independent but offers something much smaller to work with. In general, PEFT approaches allow you to get similar performance to fine-tuning a full model just by fine-tuning and adding weights.
Reinforcement Learning from Human Feedback (RLHF) is an alignment technique used after supervised fine-tuning. It incorporates human preference data to train a reward model, which guides a policy model via reinforcement learning. RLHF helps make LLM outputs more helpful, truthful, and aligned with human expectations, especially in cases where explicit rules are difficult to define.
Parameter Efficient Fine-Tuning (PEFT) is a set of techniques that enable fine-tuning large language models by updating only a small number of additional parameters while freezing the original weights.
LoRA (Low-Rank Adaptation) is a popular PEFT method that reduces compute costs, mitigates catastrophic forgetting, and produces very small checkpoints while achieving performance comparable to full fine-tuning.
Author info
