

Just a couple of years back, the title of this article would not only have sounded provocative but rather like Mission: Impossible (though, too often, without someone saving the world in the end). While many infrastructure and service operators might still remember those times when being called at 3:00 a.m. to restore a crashed server or application was not at all surprising, many would agree that this is far from being optimal. Apart from restless operators – clients that experience critical service disruptions often end up losing confidence in promised Service Level Agreements, and unhappy customers might soon be no customers of yours altogether.
But things don’t necessarily have to be that way, and in this article, we will look at:
- what GitOps is,
- why you should build your operations around it,
- and how you can use it to continuously deploy self-healing, cloud-native infrastructure and services.
What Is GitOps and Why Does it Change an Entire Industry in How Infrastructure and Applications Are Deployed, Managed, and Restored?
GitOps, introduced by Alexis Richardson in 2017, is an opiniated way of application delivery and Kubernetes cluster management. The mechanism uses the well-known source code management system Git as a single source of truth for declarative applications and infrastructure. Its inventors further describe it as a path towards increased developer experience for managing applications and infrastructure, “where end-to-end CI/CD pipelines and Git workflows are applied to both operations and development.”
Git repository
The underlying principle of GitOps is having a Git repository, containing the declarative configuration of applications and/or infrastructure currently desired in the production or any other environment. Furthermore, an automated process permanently ensures that the desired state, described in the Git repository, matches the actual state of the production environment. That means, if you want to deploy a new application or update an existing one, all you need to do is to update the Git repository – the automated process handles the rest.
To Achieve GitOps, Four Principles Must Apply

Before we dive into each principle, keep in mind that they are – by definition – principles and not specific technologies. You don’t necessarily need to replace all your existing tools, but rather still use some of them, at least if they work with Git (which I assume you use… don’t you?).
Principle 1: The entire system is described declaratively
SQL did it, HTML did it, and so does Kubernetes. Declarative means that a given configuration is guaranteed by a set of facts (what?) instead of instructions (how?). Instructions are usually programmed with languages such as Java or Python, often requiring a steeper learning curve. Meanwhile, the simple SQL query SELECT customer_id, revenue FROM customer just tells the database management system what we want, e.g., finding the customer generating the highest revenue, without giving a set of instructions on how to do it.
Getting to the declared result is entirely upon the database engine – or in our case of applications and infrastructure: upon Kubernetes. An important benefit of this is the so-called idempotence, that means it doesn’t matter how often you declare your desired state by running the automation process. If you tell Kubernetes that you always want 5 servers up and running, it will make sure to add 2 servers if currently only 3 are running or remove 1 server if 6 are running.
Meanwhile, due to the idempotence, it would do nothing if your desired state of 5 servers matches reality – as this is already exactly what you want. Imagine otherwise just giving the non-declarative instruction to “remove 2 servers now” to scale down after a traffic peak of your web shop. What if somebody already scaled down from 4 to 2 servers before you? Well… you probably won’t make it “employee of themonth” this time. Apparently, declarative systems are advantageous in such scenarios.
Principle 2: The canonical desired system state is versioned in Git
If the declaration of your system is stored in Git serving as the single source of truth, your applications can easily be deployed and rolled back to and from Kubernetes. The Git log – showing when and by whom every single line of configuration/code changed – makes rollbacks for disaster recovery, a click of a button. Your production environment went down? With GitOps, you have a complete log of how your environment changed over time, a simple “git revert” makes it possible to go back to your previous (healthy) application state, or any other snapshot for that matter.
Principle 3: Approved changes can be automatically applied to the system
As soon as you have the state declared in Git, the next step is to allow all changes to that state to be automatically applied to your system. An important advantage of this is that the declarative state repository does not necessarily need to be stored alongside the actual code of the system.
This segregation of application / infrastructure code from configuration and deployment code effectively separates what you do from how you do it. On top of that, it improves the overall security posture of the system, as developers often only need to access the application code repository.
Meanwhile, secrets and passwords can be injected into the deployment pipeline from the other repository – which might only be accessible by the operations team. And if everything is managed via Git, why not enforce a four-eyes principle to operations leveraging processes that already made history?
Let’s take the good old pull request as an example. After running through a pipeline that scans for misconfigurations and vulnerabilities before kicking off the automated deployment pipeline, it first needs to be approved by at least one other operations team member. GitOps provides an audit and transaction log to all changes done to the system, plus the possibility to double check each of them along the timeline. Thus, it makes it much harder to mess something up right from the beginning, if used together with development processes like “operations by pull request”.
Principle 4: Software agents ensure correctness and alert (diffs & actions)
Continuously monitoring the Git repository as the source of truth, software agents can inform whenever reality doesn’t match the expectations. In addition, such agents can also ensure that the system is self-healing. This is not limited to occasionally crashing servers, but human errors as well. Somebody used one of the fancy web UIs offered by AWS, Azure or GCP to mistakenly delete a firewall rule?
A software agent can compare the actual with the desired state, detect and subsequently correct that mistake by (re)applying the deleted rule. In our case, the firewall could be described by Infrastructure as Code, the provider-agnostic tool Crossplane is a popular example to facilitate this across different providers. As long as somebody told the system that firewalls might be a thing, declarative GitOps will make sure they are, even after things went wrong. This is usually done by querying the Git repository every few minutes to get the desired state as well as reconciling the actual cluster state for drift detection and correction.
After all, control agents like this are exactly the reason many operations engineers sleep much tighter nowadays, and I assume many of their clients too.
After learning what the four principles of GitOps are and why they matter, let’s have a look at how this can be put to practice!
How Does GitOps Work to Continuously Deploy, Operate, and Restore Cloud-Native Infrastructure and Services?
Throughout the last couple of years, some best practices have emerged, so keep the following in mind when starting your GitOps journey:
Environment configurations as a separate Git repository
With GitOps, the whole deployment process is organized around a central code repository. Usually, there should be two repositories: the application repository and the environment configuration repository. The application repository contains both the source code of your service and the (Kubernetes) manifest templates for deployment of the application.
The environment configuration repository contains the actual values for the deployment manifest templates of the currently desired infrastructure state. That means, it describes which applications and infrastructural services (service mesh, databases, logging and monitoring tools, etc.) are supposed to run with what configuration in the deployment environment.
Maybe you want to test your analytical database in the dev environment with a different version from QA or have your backend microservices always be scaled to at least three replicas for high availability in the production environment. All those configurations specific to each environment should be stored within the environment repository. Helm is a good example of a tool commonly used for Kubernetes configuration templates. Moreover, doing rollbacks and browsing the Git history is much easier with one repository for each development and operation.
Pull-based deployments
CI/CD pipelines are traditionally triggered by some event, for example when code is pushed to an application repository. When leveraging the pull-based approach to deployment, the so-called operator pattern is introduced. Basically, an operator is codified operational knowledge. It takes over the CD part of the CI/CD pipeline by continuously comparing the actual state in the deployed infrastructure with the desired state in the environment repository. If it spots a difference, the operator will do its job to automatically reconcile the infrastructure in a way to match the environment repository (again).
Additionally, the application image registry can be monitored to check for new versions of images to deploy.
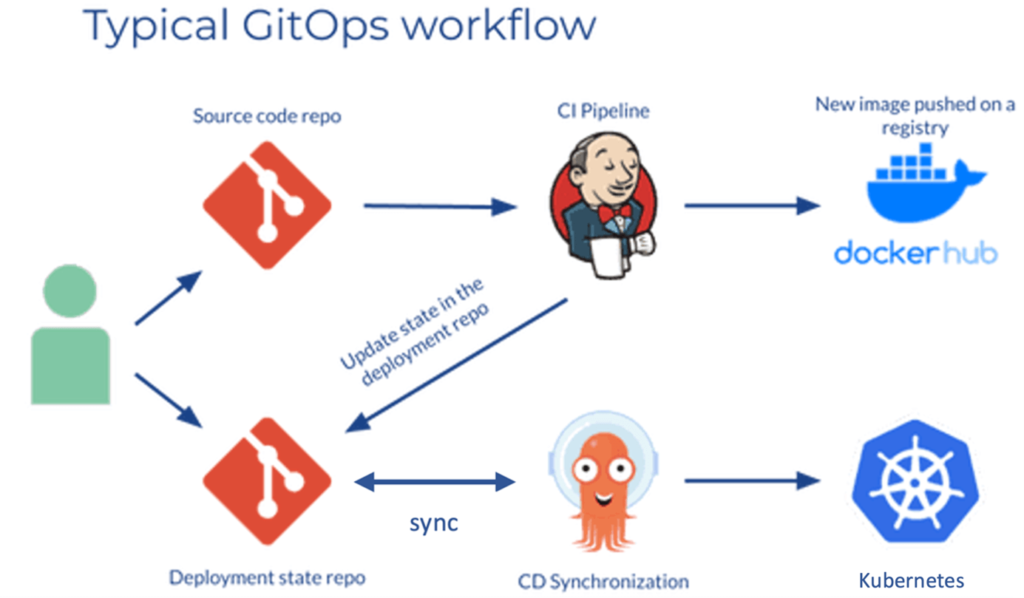
Equal to push-based deployments, traditionally done with pipeline tools such as Jenkins or Github Actions, pull-based deployments change the environment whenever the underlying environment repository changes. However, an operator detects changes mutually.
An example
For example, if your new intern tried out what happens when deleting one of those many confusing Kubernetes namespaces – accidentally deleting your production backend. Whenever your deployed service or infrastructure changes in any way not described in the environment repository, these changes are automatically reverted, in our example recreating the namespace and all production backend services.
In comparison, traditional push-based CI/CD methods only update the environment when the underlying configuration repository is updated – often leading to a blind spot in between those updates. However, don’t forget to monitor your deployment operator, as without it you now won’t have any automated deployment at all.
Final Thoughts
GitOps fundamentally changes the way things are being operated. If we take it seriously, I’d argue we should introduce a new pattern to solve our problems: Everything-as-Code.
Imagine that not only your applications and infrastructure, but literally all configurations, security policies, logging, monitoring and alerting, as well as advanced rollout strategies like canary deployments, are being stored in and automated from Git – making it possible to automatically go from nothing at all to productionized, highly available and secure services within minutes – even if disaster strikes. Chances are you will sleep more peacefully.
Photo by Miriam Alonso on Pexels