
Mittlerweile dürfte wohl überall angekommen sein, dass ein solides Datenmanagement die unverzichtbare Basis für Unternehmen ist, die ihren Einsatz von KI ausbauen oder verbessern wollen. Aber was nun? Sobald die Grundlagen stehen, eine funktionierende Data Governance etabliert ist und Zuständigkeiten klar geregelt sind, lohnt ein Blick auf die aktuellen Entwicklungen. Und ja, davon gibt es eine ganze Menge. Genau aus diesem Grund schreiben wir diesen Artikel: Damit du dich in den nächsten Minuten nur mit den relevantesten Trends auseinandersetzen musst.
*** Disclaimer: Wir geben keine Garantie auf Vollständigkeit, aber auf einen soliden Überblick in etwa 10 Minuten.^^ ***
Mit einem kritischen Blick auf die Schnittstellen zwischen Datenmanagement und KI zeigen wir dir 5 Trends vor, die die digitale Transformation in Organisationen 2026 vorantreiben (können). Gleichzeitig werfen wir einen Blick zurück auf einige im letzten Jahr von uns aufgeführte Datenmanagement-Trends und analysieren, wie sie sich weiterentwickelt haben.
Übersicht
- Eine neue Führung: Chief Data Officer (CDO), Chief AI Officer (CAIO) und Governance-by-Design
- Data Provenance für mehr Vertrauen in Daten und erfolgreiches Metadatenmanagement
- Produktisierung von Daten und Agent Experience (AX)
- DataOps 2.0: KI-nativ und mit konversationellem Datenzugriff
- Echtzeit- & eventgetriebenes Datenmanagement
Falls du zuallererst eine kurze Auffrischung möchtest:
“Datenmanagement ist die Praxis einer Organisation, ihre Daten zu sammeln, zu speichern, zu verarbeiten und zu sichern, mit dem Ziel, den Wert der Datennutzung für alle verschiedenen Geschäftsprozesse zu maximieren.”
– Malina Iorga, Senior Manager Growth Marketing bei Diconium Romania in “5 Datenmanagement Trends in 2025”
1. Eine neue Führung: Chief Data Officer (CDO), Chief AI Officer (CAIO) und Governance-by-Design
Der Aufstieg des Chief Data Officers (CDO)
Fangen wir mal mit dem allerersten Trend an, der eher ein schleichender Prozess als eine bahnbrechende Neuigkeit ist: Die Rolle des Chief Data Officers, kurz CDO, war noch nie so präsent wie in diesem Jahr. Die erst kürzlich mit industrieübergreifenden Repräsentant:innen aus der Führungsebene durchgeführte 2026 AI & Data Leadership Executive Benchmark Survey ergab, dass bei der ersten Umfrage 2012 noch 12 % der befragten Unternehmen einen Chief Data Officer ernannten – diese waren vor allem in Finanzinstitutionen. Über die Jahre entwickelte sich die Rolle weiter und legte den Fokus nicht mehr nur noch auf Risiken und Regulierung, sondern auch auf das Geschäftswachstum, das durch das Potential von Daten erkannt wurde, und wuchs so von einer eher defensiven zu einer offensiveren, innovationsgetriebenen Rolle.
In vielen Organisationen ist mittlerweile die Funktion eines Chief Data and Analytics Officers, kurz CDAO, gewachsen. Und heute, 2026? Haben bereits 90 % der Unternehmen einen CDO oder CDAO ernannt.
Der Chief AI Officer (CAIO): Konkurrenz, Koexistenz oder „same same but different”?
Parallel dazu etabliert sich in vielen Unternehmen eine weitere Führungsrolle: der Chief AI Officer, kurz CAIO. Während diese Funktion vor wenigen Jahren noch kaum existierte, haben inzwischen 38,5 % der Organisationen einen CAIO oder eine vergleichbare Rolle benannt; Tendenz steigend. Gleichzeitig zeichnet sich ein klarer Trend ab: Erste Unternehmen führen Daten-, Analytics- und AI-Verantwortung in einer gemeinsamen Rolle zusammen. In Organisationen ohne CAIO liegt die Verantwortung für AI allerdings weiterhin meist beim CDO. Das könnte ein Hinweis darauf sein, dass die Rollen mittelfristig eher zusammengeführt werden als dass sie dauerhaft nebeneinander existieren.
An dieser Stelle ein paar offene Gedanken zur Einordnung dieser Rollen:
- Fasst ein Unternehmen KI als isolierte Technologie auf, ergibt eine Trennung von CDO und CAIO Sinn. In der Praxis ist KI jedoch vollständig auf Datenqualität, -zugang und -governance angewiesen und eine Zusammenlegung der Rollen könnte inhaltlich Sinn ergeben – ob auch organisatorisch, hängt wohl vom Unternehmen ab.
- Sollte ein Chief AI Officer nicht mindestens ein ebenso tiefes Verständnis für Datenarchitekturen, Datenqualität und Datenverantwortung haben wie ein CDO? Denn ohne dieses Fundament bleibt der Einsatz künstlicher Intelligenz strategisch oberflächlich oder operativ riskant.
- Bei getrennten Rollen die Gefahr von Verantwortungsdiffusion: Wer ist am Ende für fehlerhafte Modelle, unklare Datenherkunft oder regulatorische Risiken verantwortlich: Chief of Data oder AI…?
- Eine zu breite Verantwortung wiederum könnte ohne entsprechendes Mandat, Budget oder organisatorische Durchgriffskraft dazu führen, dass weder Daten noch KI wirklich gut gesteuert werden, was in einer Lose-Lose-Situation endet.
Die Notwendigkeit von Governance-by-Design
Data Governance, im Deutschen auch manchmal Daten-Governance genannt, ist die strategische oberste Ebene im Datenmanagement. Sie baut auf gut strukturierten Daten und konstanter Datenqualität auf und betrachtet Daten aus einer strategischen Perspektive. Data Governance zeigt, wie man Daten nutzen kann, um langfristigen geschäftlichen Nutzen zu erzielen, zum Beispiel Umsatzwachstum durch präzise Kundendaten oder die Entwicklung innovativer Datenprodukte. Wirklich umsetzbar wird Data Governance aber erst, wenn eine solide Basis im Datenmanagement vorhanden ist, sonst bleibt sie reine Theorie.
Wenn Daten- und KI-Verantwortung zunehmend zusammengeführt werden, reicht ein bisschen Governance on top nicht aus. Sie muss direkt in Strukturen, Rollen und technische Prozesse eingebaut sein, auch Governance-by-Design genannt.
Governance-by-Design ist ein starkes Thema für durchdachtes Organisations- und Führungsdesign und bedeutet konkret, klare Ownerships für Domänen und Datenprodukte zu schaffen und definierte Entscheidungsrechte festzulegen (wer darf was freigeben, verändern, deployen). Eine gut umgesetzte Governance-by-Design macht manuelle Freigaben überflüssig, reduziert Fehler und Inkonsistenzen und beschleunigt Entscheidungen, weil Zuständigkeiten von vornherein klar definiert sind. Praktisch zeigt sich das etwa in automatisierten Qualitätsprüfungen innerhalb der Datenpipelines, vordefinierten Genehmigungsworkflows für Datenprodukte, eingebauten Compliance-Checks bei jedem Deployment oder durch Self-Service-Datenkataloge, die Teams klare Ownership- und Zugriffskonzepte bieten.
Passend dazu kann ich dir den Artikel meiner Kollegin empfehlen, falls dich das Thema Self-Service im Datenkontext interessiert: Daten für Alle durch Self-Service-Analytics demokratisieren.
2. Data Provenance für mehr Vertrauen in Daten und erfolgreiches Metadatenmanagement
Was ist Data Provenance?
Provenance bedeutet im Deutschen so viel wie Herkunft oder Ursprung. Data Provenance bezieht sich auf die Dokumentation, woher Daten stammen und welche Transformationen sie durchlaufen haben. Sie gibt Auskunft über die Authentizität der Daten, wer sie erstellt hat, welche Änderungen vorgenommen wurden und von wem.
Man kann sich Data Provenance gut am Beispiel eines journalistischen Prozesses vorstellen: Angenommen, wir führen ein Interview und nehmen es auf. Wir speichern die Aufnahme, dokumentieren, wer interviewt hat, wer interviewt wurde sowie Datum und Uhrzeit. Um daraus einen Artikel zu erstellen, kürzen wir das Transkript, schneiden Füllwörter heraus und markieren jede Bearbeitung als Update, damit andere erkennen, dass das Dokument verändert wurde und nicht mehr dem ursprünglichen Text entspricht. Für die Headline entnehmen wir vielleicht ein kurzes Zitat. Im Optimalfall wird auch der historische Kontext dokumentiert, also wann und in welchem Zusammenhang Aussagen gemacht wurden.
Fehlt diese Dokumentation, wird schnell unklar, welche Informationen vertrauenswürdig sind, welche Änderungen stattgefunden haben und wie bestimmte Daten oder Zitate überhaupt entstanden sind. Das kann zu Fehlern, Missverständnissen oder falschen Entscheidungen führen… Probleme, die in allen datenbasierten Prozessen auftreten können.
Warum brauchen wir Data Provenance?
- Stellt die Genauigkeit und Rechtskonformität von Daten sicher
- Fördert einen transparenten Umgang mit Daten und kann so das Vertrauen innerhalb eines Unternehmens und auch in ein Unternehmen stärken
- Erleichtert die Bewertung von Datenqualität für Geschäftsanwendungen
- Unterstützt fundierte Entscheidungen bei neuen Produkten oder KI-Modellen, weil nachvollziehbar ist, auf welcher Datenbasis gearbeitet wird
- Sichert die Datenqualität auch bei Teamwechseln oder wenn Mitarbeitende das Unternehmen verlassen, sodass Informationen konsistent und verlässlich bleiben
Wie Metadatenmanagement uns bei Data Provenance unterstützt
Metadatenmanagement liefert die notwendige Struktur und Übersicht, damit Data Provenance überhaupt möglich wird. Gutes Metadatenmanagement sorgt dafür, dass Informationen zu Datenherkunft, Änderungen, Verantwortlichkeiten und Kontext systematisch erfasst, verknüpft und zugänglich sind. So lassen sich Abläufe nachvollziehen, Fehler schneller identifizieren und Datenprodukte effizienter nutzen.
Für eine transparentere Datenherkunft: die Data Provenance Initiative
Eine ganz spannende Entwicklung ist hier zum Beispiel die Data Provenance Initiative von KI-Forschenden aus aller Welt. Sie haben sich zusammengeschlossen, um groß angelegte Audits von Datensätzen durchzuführen, die zum Training von KI-Modellen verwendet werden. Konkret untersuchen sie große, häufig genutzte Trainingsdatensätze wie Texte, Videos und Audios hinsichtlich Herkunft, Lizenzen, Urheber:innen und Nutzungsbedingungen.
Die Mitglieder der Initiative bauen ein transparentes, öffentlich einsehbares „Provenance“-Register, mit dem sich nachvollziehen lässt, woher die Daten stammen und ob sie rechtlich und ethisch sauber nutzbar sind. Sie stellen außerdem Daten, Audits und Tools öffentlich zur Verfügung, damit Modellhersteller, Forschende und Unternehmen fundiertere Entscheidungen treffen können. Ihr Ziel ist es, Transparenz, Verantwortlichkeit und Rechtskonformität in der KI-Entwicklung zu verbessern, indem sie nachvollziehbar machen, auf welcher Datenbasis Modelle trainiert wurden.
Auch wenn es die letzten Monate etwas stiller um sie geworden ist, bleibt es sicher nicht die einzige Initiative in eine solche Richtung.
Bildquelle: Screenshot des Dataset Explorers – https://www.dataprovenance.org/data-provenance-explorer/dataset-explorer
3. Produktisierung von Daten und Agent Experience (AX)
Unser dritter Datenmanagement-Trend dreht sich darum, Daten als Produkt zu denken – und was das für ihre Behandlung bedeutet. Daten werden ähnlich wie ein klassisches Software-Produkt verstanden, mit:
- Einem klar benannten Product Owner
- Einer Roadmap mit Zielen, Meilensteinen und Launches
- Einer möglichst nutzerzentrierten Entwicklung, die konkrete, vorher identifizierte Bedürfnisse adressiert (auf die Frage, wer diese Nutzer nun genau sind, kommen wir gleich zurück)
- Definierten Qualitätsstandards, gegen die kontinuierlich getestet wird
- Einem MVP, das früh mit den späteren Usern getestet und iterativ weiterentwickelt wird
Gleichzeitig gibt es keine einheitliche, „offizielle“ Definition von Datenprodukten. Es gibt nicht die eine Single Source of Truth. IBM unterscheidet zum Beispiel noch einmal zwischen Data Products und DaaP (Data as a Product): DaaP beschreibt eine ganzheitliche Methode, Daten als marktfähiges Produkt inklusive Code, Daten, Metadaten und Infrastruktur bereitzustellen, etwa in Form einer Customer-Insights-Plattform, die alle Touchpoints eines Retailers zu einem 360°-Kundenbild zusammenführt. Data Products dagegen nutzen diese Datenbasis für konkrete, weitergedachte Lösungen wie Dashboards, Predictive Models oder Chatbots und fokussieren sich damit auf klar abgegrenzte Anwendungsfälle.
Warum lohnt es sich, Daten als Produkt zu denken?
- Ein klar definierter Use Case erleichtert die Auswahl der Daten. Ein Produkt muss nicht zig Ziele gleichzeitig erfüllen, sondern kann eines besonders gut unterstützen.
- Klarere Verantwortung führt im Idealfall dazu, dass Wissen über vorhandene Daten gebündelt wird und aktiver geteilt werden kann.
- User-zentriertem Design wird mehr Bedeutung zugemessen. Das kann die tatsächliche Nutzung steigern und sorgt dafür, dass Nutzer ihre Ziele schneller erreichen können (z.B. „In Power BI importieren“-Button statt nur SQL-Tabelle).
- Ein klarer Produktzyklus (von Discovery bis Decommissioning (= Außerbetriebnahme)) hilft, Prozesse zu strukturieren und wiederkehrende Probleme systematisch statt ad hoc zu lösen.
Wenn wir Daten also als Produkt denken, stellt sich automatisch die Frage: Wer sind eigentlich die Nutzer und wie greifen sie darauf zu? Neben Teammitgliedern, Kunden und anderen Menschen werden inzwischen auch KI-Agenten zu wichtigen Usern. Die schauen wir uns als Nächstes genauer an:
KI-Agenten: Die neuen User von Datenprodukten
Erst vor ein paar Tagen bin ich über einen ganz interessanten Blogartikel gestolpert: “Why the Future of Data Platform Engineering is Agent Experience (AX)”. Darin argumentiert Robert Sahlin, Data Platform Engineering Manager, dass Plattformen nicht mehr primär Dev-first, sondern Agent-first sein müssen. KI-Agenten werden zu den neuen Hauptnutzern und benötigen smoothen, zuverlässigen Daten-Zugriff ohne menschliche Umwege.
“We assumed the end user would always be a human sitting at a desk, looking at a screen. My work over the last six months has forced me to rethink everything. The developer we are building for is no longer just a human. As we move deeper into 2026, it is clear that AI agents will do the heavy lifting in coding and system management. If we continue to build for human eyes only, we will inevitably become the bottleneck in our own systems.”
– Robert Sahlin in “Why the Future of Data Platform Engineering is Agent Experience (AX)”
Sahlins Logik gilt nicht nur für Data Platforms, sondern genauso für Datenprodukte selbst. Ein gutes Datenprodukt 2026 muss nicht nur für Menschen, sondern genauso für Agents verständlich sein: strukturiert, vorhersagbar, API-first. Einige seiner neuen Prinzipien lauten daher:
- Programmatisch vor visuell: Ein Agent brauche maschinenlesbare Schnittstellen, keine Suchoberfläche mit Web-UI-Buttons.
- Strukturierte Schemata: Dokumentation müsse standardisiert maschinenlesbar sein. Keine langen Wikis mehr, sondern strikte APIs, Tech-Specs und Metadata-Dateien, die klar definieren, was das Tool kann und was nicht. Ein LLM müsse das sofort erkennen können.
- Standards für autonome Auffindbarkeit: damit Agenten Datenprodukte und Tools plattformübergreifend selbst finden und nutzen können.
Von Developer Experience (DX) zur Agent Experience (AX)
Damit wird die User Experience von KI-Agenten – die Agent Experience (AX) – zur logischen Weiterentwicklung der Produktisierung von Daten. Sahlin formuliert es treffend: „Stop being designers of user journeys and start being architects of agentic protocols.“ Heißt das jetzt komplett weg von ästhetisch ansprechender UI? Nicht ganz. Wie so oft gilt auch hier: Use Case first. Wenn das Datenprodukt primär von Menschen genutzt wird, ist Agent-First nicht immer der richtige Weg. Aber AX im Hinterkopf zu haben, wenn man neue Datenprodukte entwickelt, schadet definitiv nicht.
Fazit: Das Grundprinzip bleibt gleich… starte beim User und dessen Wünschen und Bedürfnissen. Ob nun Mensch oder Agent.
Der Ort, an dem Innovation Form annimmt: Diconiums Data Product Factory
Auch bei Diconium spielen Datenprodukte eine wachsende Rolle. Die Data Product Factory ist dabei unser Experimentierfeld, in dem die Datenprodukte von morgen entstehen. Hier verwandeln die kreativsten Köpfe unseres Teams innovative Ideen in marktreife Lösungen mit einem maßgeschneiderten Programm, in dem unser Enabler-Team Seite an Seite mit Data Scientists, Data Engineers, AI-Experts und Legal Specialists arbeitet.
Wie kam es dazu? Die unterschiedlichen Standorte Diconiums sind schon lange ein Schmelztiegel unterschiedlichster Hintergründe. In dieser Atmosphäre entstehen ständig Ideen für Datenprodukte, von denen einige direkt als Kunden-Folgeprojekte weiterentwickelt werden. Eine vage, aber spannende Idee war zu roh für direkte Kundenarbeit, also wurde sie in der Factory nebenher umgesetzt und nach vielen Iterationen stand ein robustes Framework, um Datenprodukte erfolgreich zu launchen.
Neben dem kreativen Raum bietet die Factory ein 4-Phasen-Programm (Exploration → Design → Umsetzung → Launch), das auf Learnings aus früheren Projekten und bewährten Lean-Startup-Methoden basiert. So wird aus spontaner Inspiration ein echtes Produkt. Lies mehr dazu auf unserer Data Product Factory Landingpage.
Bildquelle: https://applydata.io/customer-lifetime-value/
Data Fabric macht Datenprodukte möglich
Vor einem Jahr haben wir Data Fabric noch als eigenständigen Megatrend gefeiert; die Technologie, die Silos aufbricht und Daten aus allen Ecken zu einem nahtlosen Puzzle zusammensetzt.
“Der Begriff Data Fabric wird verwendet, um eine Datenmanagementarchitektur zu beschreiben, die darauf ausgelegt ist, einen nahtlosen und konsistenten Zugang zu und Verwaltung von Daten aus verschiedenen Quellen zu ermöglichen, einschließlich lokaler Systeme, cloudbasierter Systeme und anderer Arten von Datenspeichern.
Eine Data Fabric umfasst typischerweise eine Reihe von Tools und Technologien, die Datenintegration, Datenmanagement und Datenverwaltung im gesamten Daten-Ökosystem einer Organisation ermöglichen. Das Ziel einer Data Fabric ist es, Organisationen den Zugriff auf ihre Daten zu erleichtern und sie zu nutzen, um Erkenntnisse zu gewinnen, bessere Entscheidungen zu treffen und Geschäftsergebnisse zu verbessern.
Was eine Data Fabric letztendlich tut, ist höhere Effizienz durch den Einsatz von ML/AI zu ermöglichen und gleichzeitig Geschäftsteams zu befähigen, autonom als Datennutzer zu agieren und umsetzbare Erkenntnisse zu gewinnen.”
– Malina Iorga, Senior Manager Growth Marketing bei Diconium Romania in “5 Datenmanagement Trends in 2025”
Was ist 2026 draus geworden? Data Fabric ist nicht verschwunden, sondern hat sich als der technische Unterbau erwiesen, der Datenprodukte überhaupt erst möglich macht. Datenprodukt-Teams müssen sich nicht mehr mit Integration-Chaos rumschlagen, sondern können sich auf User Needs oder eben auch AX konzentrieren. Fabric läuft leise im Hintergrund und hält die Daten verfügbar, während vorne die Produkte Gestalt annehmen.
4. DataOps 2.0: KI-nativ und mit konversationellem Datenzugriff
“DataOps ist eine Reihe von Praktiken innerhalb eines kollaborativen Datenmanagementmodells, das darauf abzielt, die Lücke zwischen Domain-Datenbesitzern und Datennutzern zu schließen. Um den Wert von Daten zu liefern, müssen Organisationen die Nutzung von Analysen beschleunigen und datengetriebene Entscheidungsfindung ermöglichen. In den Fußstapfen von Methoden wie DevOps und DevSecOps kommen DataOps-Teams zusammen, um die Geschwindigkeit der Analysen im Unternehmen zu beschleunigen und in umsetzbare Business Intelligence zu übersetzen. Die Methodologie von DevOps wird mit Datenspezialisten wie Dateningenieuren und Datenwissenschaftlern erweitert. Das Ziel ist es, Datenströme und die kontinuierliche Nutzung von Daten im gesamten Unternehmen zu ermöglichen.”
– Malina Iorga, Senior Manager Growth Marketing bei Diconium Romania in “5 Datenmanagement Trends in 2026”
Im vergangenen Artikel “5 Datenmanagement Trends in 2025” nannten wir den “Aufstieg von DataOps” sowie “Automatisierung und KI” als zwei separate Trends. Und auch dieses Jahr müssen sie wieder ihren Platz in diesem Artikel finden – aber gemerged, denn sie gehören eng zusammen.
DataOps schließen die Lücke zwischen Domain-Datenbesitzern und Nutzern, indem sie DevOps-Praktiken auf Datenpipelines anwenden: kontinuierliche Integration, Testing und Deployment für Analysen, die datengetriebene Entscheidungen beschleunigen. Und DataOps 2.0 ist KI-nativ: Machine Learning wird direkt in die Pipelines eingebettet und wird Kern der Architektur. Was bedeutet KI-nativ konkret? Stell dir Pipelines vor, die Datenveränderungen (Drift) automatisch erkennen, bevor Queries scheitern, zum Beispiel wenn sich Kundenverhalten ändert oder Quellen neue Formate liefern. KI überwacht Metriken, retraint Modelle selbstständig und behebt Anomalien.
Konversationeller Datenzugriff erleichtert den Daten-Self-Service
Manchmal ist Reden einfach schneller als Tippen: Seit letztem Jahr bieten Unternehmen vermehrt sprachbasierte KI-Assistenten (auch einfach Conversational AI genannt) an, wie zum Beispiel als Datenanalyse-Assistenten zum Interpretieren und Einordnen vorhandener Big Data oder als integriertes Tool für einen einfachen und schnellen Datenabruf. NLP (Natural Language Processing) Interfaces unterstützen die Demokratisierung von Daten und Barrierefreiheit auch für Menschen mit Schreibschwäche oder Hörbeeinträchtigung. Natürliche Sprache macht Daten für alle Teams zugänglich und greifbar, ohne unbedingt Query-Syntax oder BI-Tool-Schulungen lernen zu müssen.
Konversationsbasierte KI in der Datenanalyse
Du könntest zum Beispiel fragen: “Zeig mir den Umsatz Q1 2026 pro Region, mit Prognose und meistverkauftesten Produkten”. Die Conversational AI ist auf LLMs aufgebaut und versteht nicht nur die Worte, sondern Kontext, Nuancen und deine Absicht. Stellst du Folgefragen wie “Was wäre, wenn wir Preise um 5% senken?” kannst du schnell Antworten auf deine wichtigsten Fragen finden. Gerade in der Analyse großer Datenmengen kann KI eine gute Unterstützung sein. Trotzdem sollte der eigene kritische Blick nicht verloren gehen, denn vage Fragen können zu Fehlinterpretationen führen. Auch eine solide Governance ist nötig, um Sicherheitsstandards und Datenzugriff klar zu definieren.
Auch in Onlineshops kommen konversationsbasierte KI-Agenten zunehmend zum Einsatz und verwandeln den traditionellen E-Commerce in KI-Commerce. Falls du mehr dazu erfahren möchtest, lies hier weiter: Was ist Conversational AI und wie kann sie Online-Shop-Betreibende unterstützen?
5. Echtzeit- & eventgetriebenes Datenmanagement
Wir kommen bereits zum letzten Trend in 2026: Echtzeit- & eventgetriebenes Datenmanagement. Doch was bedeutet das genau? Daten werden nicht mehr in Batches verarbeitet (also nicht stunden- oder tageweise in großen Stapeln offline hochgeladen), sondern live. Getriggert durch Events wie Kundenaktionen (z. B. Abbruch des Warenkorbs), Sensormeldungen oder Marktveränderungen reagieren Systeme sofort auf Ereignisse.
Warum ist das jetzt relevant? Kunden haben sich mittlerweile an Personalisierung in Echtzeit gewöhnt, Lieferketten brauchen Störungsalarme, Agenten autonome Live-Daten für dynamische Entscheidungen.
Event Streaming für schnelle Live-Datenverarbeitung
Zentral befindet sich sogenanntes Event Streaming, das über Technologien wie Apache Kafka oder Apache Flink läuft. Kafka transportiert die Events (= Nachrichten/Informationen) schnell von A nach B und sorgt dafür, dass nichts verloren geht. Flink baut darauf auf und verarbeitet die Daten direkt, ohne dass alles zentral in einer Cloud landen muss. Und laut einer Marktanalyse von Mordor Intelligence ist der globale Markt für Event Stream Processing konstant am Wachsen: Während er 2025 noch mit etwa 1,41 Milliarden USD und 2026 mit 1,61 Milliarden USD bewertet wurde, soll er bis 2030 noch auf 2,94 Milliarden USD ansteigen.
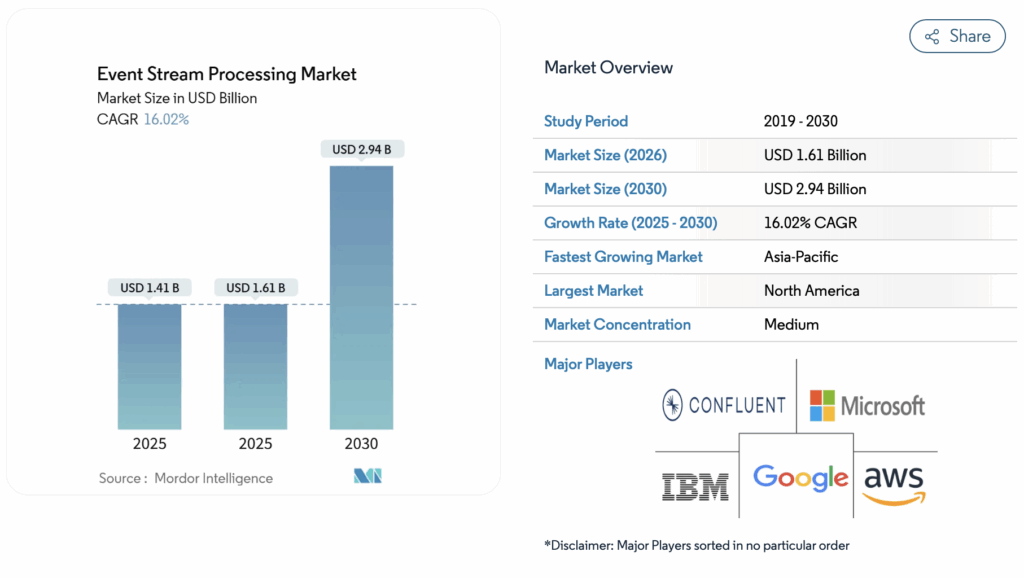
Bildquelle: Mordor Intelligence Research & Advisory. (2026 , February). Event Stream Processing Market Size & Share Analysis – Growth Trends and Forecast (2026 – 2031). Mordor Intelligence. Retrieved May 5, 2026, from https://www.mordorintelligence.com/industry-reports/event-stream-processing-market
Yingjun Wu, Founder & CEO von RisingWave, lieferte tiefere Einblicke in das Thema Event Streaming auf unserem Berliner applydata Meetup: Er erklärte in seiner Keynote “Achieving Sub-100ms Real-Time Stream Processing with an S3-Native Architecture”, wie man mit solchen Systemen unter 100 ms Latency kommt.
Edge Analytics: von Trend zu Basis für echtzeit- & eventgetriebenes Datenmanagement
2025 führten wir unter anderem auch Edge Analytics als Trend auf, weil immer mehr vernetzte Geräte und Fahrzeuge Daten direkt am Entstehungsort auswerten mussten, z. B. Fahrzeuge, die Ladevorgänge und Sensordaten lokal analysieren, oder Maschinen, die Anomalien direkt am Band erkennen.
Edge Analytics bezeichnet die erste Analyse von Daten auf oder nahe von Devices (z. B. Bordcomputer im Auto, IoT-Geräte), anstatt alle Daten ungefiltert in die Cloud zu schicken. Das spart Bandbreite, reduziert Latenz und unterstützt die Einhaltung des Datenschutzes, gerade in Branchen wie Automotive oder Healthcare.
Inhaltlich ist Edge Analytics heute weniger ein eigener Trend, sondern ein Fundament des größeren Themas Echtzeit- & eventgetriebenes Datenmanagement. Events wie Sensordaten oder Nutzerinteraktionen werden am Edge vorverarbeitet oder bewertet und dann in Streams weitergegeben. So erkennen Devices Ereignisse in kürzester Zeit, treffen erste Entscheidungen lokal und leiten nur noch relevante Events in zentrale Streaming-Architekturen weiter.
Edge Analytics bei Diconium
„In unserer langjährigen Geschichte im Mobilitätssektor haben wir Edge Analytics für mehrere Projekte genutzt:
Fahrzeugdaten
In Zusammenarbeit mit einem deutschen Automobilhersteller in den Monaten vor der Veröffentlichung ihres E-Automodells entwickelten unsere Kollegen eine App, die sich nahtlos mit Ladestationen integriert. Die Lösung ermöglicht es Autobesitzern, auf Daten von Ladestationen am Edge zuzugreifen und ihre Reisen im Voraus mit voller Vorhersehbarkeit in Bezug auf Anbieter, Standorte, Verbindungen und mehr zu planen.
Monetarisierung von Daten
Für das zweite Projekt arbeiteten wir mit einem B2B-Automobilunternehmen zusammen, das enorme Mengen an Sensordatenpunkten sammelt. Unsere Aufgabe war es, das finanzielle Potenzial ihrer Datenbestände zu ermitteln, was uns zu einem kritischen Punkt in der Diskussion über Datenkapital bringt – die Monetarisierung. Da alle Unternehmen im Geldgeschäft tätig sind, kann Edge Analytics wertvolle Monetarisierungsquellen für Unternehmen liefern, die ihre Einnahmequellen diversifizieren möchten.“
– Malina Iorga, Senior Manager Growth Marketing bei Diconium Romania in “5 Datenmanagement Trends in 2025”
Zusammenfassung unserer 5 Datenmanagement-Trends in 2026
Wir haben dir unsere 5 Datenmanagement-Trends für 2026 vorgestellt: organisatorisch relevante Einführungen von Rollen wie Chief Data Officer (CDO) und Chief AI Officer (CAIO), Data Provenance für mehr Vertrauen in Daten, die Produktisierung von Daten und den Fokus auf Agent Experience (AX), KI-native DataOps 2.0 mit konversationellem Datenzugriff sowie echtzeit- & eventgetriebenes Datenmanagement. Je schneller sich alles weiterentwickelt, desto größer wird die Gefahr, sich zu verzetteln. Entscheidend ist, die Trends rauszupicken, die wirklich einen Mehrwert bringen.
Welche Trends fehlen dir noch auf unserer Liste? Und welche davon werden deiner Meinung nach auch 2027 noch relevant sein?
Author info
