
In recent years, Generative AI has become a more popular and rapidly evolving technology. Its capabilities are expanding rapidly as new research is being conducted. In the context of generative AI models, Foundation models have become a more powerful tool which can be used as a fundamental binding block for various downstream tasks. LLMs and Diffusion models are a part of Foundation models.
In this post, we will start with an overview of Foundation models, Diffusion models and Large Language Models (LLMs). Afterwards, we will dive deeply into the possibilities of development with LLMs.
What are Foundation Models?
Foundation models are designed to learn from large amounts of data and to perform a wide variety of tasks. They are often used in natural language processing (NLP), computer vision, and speech recognition. Foundation models are typically trained on massive datasets, such as the entire Wikipedia or the trillions of words that are produced on the internet every day. This allows them to learn the relationships between words and concepts, and to develop a deep understanding of the world.
What foundation models can do
Foundation models are still under development, but they have already achieved impressive results in a variety of tasks. For example, they can generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way.
What Are Benefits and Challenges of Foundation Models?
There are several benefits to using foundation models and challenges associated with foundation models:
| Benefits of Foundation Models | Challenges of Foundation Models |
| Accuracy: Foundation models can achieve state-of-the-art results on a wide variety of tasks. This is because they can learn from massive amounts of data and generalize to new tasks. | Bias: Foundation models can be biased against certain things, such as groups of people. This is because they are trained on data that is often biased, and they can perpetuate these biases in their predictions. |
| Robustness: Foundation models are able to handle noisy data and to perform well even when they are given incomplete or incorrect information. This is because they are able to learn the underlying patterns in the data, rather than simply memorizing specific examples. | Interpretability: Foundation models can be difficult to interpret, which can make it difficult to understand why they make the decisions they do. This can be a problem for tasks such as medical diagnosis, where it is important to be able to explain why a particular decision was made. |
| Flexibility: Foundation models can be used for a wide variety of tasks, from natural language processing to computer vision. This is because they are able to learn the relationships between different types of data. | Safety: Foundation models can be used to create malicious or harmful content, such as fake news or deepfakes. This is a serious concern, and it is important to develop ways to mitigate these risks. |
Foundation models are a powerful new tool that has the potential to revolutionize a wide variety of industries. However, it is important to be aware of the challenges associated with these models, and to take steps to mitigate these risks.
What Are Diffusion Models?
Diffusion models are a class of generative models and an example of foundation models for computer vision that have recently gained popularity due to their ability to generate high-quality images and videos. Diffusion models are based on the idea of diffusion processes, which are stochastic processes that describe the spread of a substance over time.
Diffusion models in the context of generative modelling
In the context of generative modelling, diffusion processes are used to model the way that information spreads through a latent space, which is a high-dimensional space that represents the underlying structure of the data. The key concept in Diffusion Modelling is that if we could build a learning model that can learn the systematic decay of information due to noise, then it should be possible to reverse the process and therefore, recover the information from the noise.
More characteristics of diffusion models
Diffusion Models are adaptable and can use any architecture with the same input and output dimensions. Many implementations use U-Net-like architectures. The training objective is to maximize the likelihood of the training data. This is done by tuning the model parameters to minimize the variational upper bound of the negative log-likelihood of the data.
Ultimately, using a simplified training objective to train a function that predicts the noise component of a given latent variable produces the best and most stable results. Diffusion models can also act as Foundation models for NLP and different multimodal generation tasks like text to video and text to image as well.
Examples of diffusion models
DALL-E by OpenAI, Stable Diffusion by Stability AI, Midjourney by Midjourney, Inc, Imagen for generating images and Imagen Video for generating videos by Google are some notable diffusion models.
What Are Large Language Models (LLMs)?
Large language models (LLMs) are also a class of generative models and examples of foundation models that can understand and generate human language. They are trained on massive datasets of text, and they can learn to perform a wide variety of tasks, such as translating languages, writing different kinds of creative content, and answering your questions in an informative way. This dataset can be anything from news articles to social media posts to books. The LLM is then able to learn the relationships between words and phrases, and it can use this knowledge to understand and generate new text.
LLM vs. human
LLMs are often compared to human brains because they can learn and adapt similarly. However, LLMs are still far from being able to match the full capabilities of the human brain. For example, LLMs can struggle to understand sarcasm or humor, and they can sometimes produce nonsensical or offensive text.
Despite these limitations, LLMs are still very powerful tools. They can be used to perform a wide variety of tasks, including:
- Translation: LLMs can translate languages with a high degree of accuracy.
- Summarization: LLMs can summarize long pieces of text into a concise and informative format.
- Question answering: LLMs can answer your questions in an informative way, even if the questions are open-ended or challenging.
- Chatbots: LLMs can be used to create chatbots that can engage in natural conversations with humans.
- Creative writing: LLMs can be used to generate original works of art and literature, such as poems, songs, and short stories.
Examples of LLMs
GPT (GPT-3, GPT-4 etc.) by OpenAI, PaLM by Google, Dolly by databricks, Llama by Meta, Claude by Anthropic are some notable large language models.
How To Apply Large Language Models in Practice: In-Context Learning, Fine-Tuning, Pre-Training
Large Language Models (LLMs) have completely revolutionized the process of training ML models for language tasks with the advent of Transformers in 2017. Previously, for a given task and a given dataset, we would experiment with various models such as RNNs, LSTMs, Decision Trees, etc. by training each of them on a subset of the data and testing on the rest. The model that gave the best accuracy was chosen as the winner. Also, a lot of model hyper-parameters needed to be tuned with experimentation and for many problems, feature engineering was also necessary.
With the advent of transformer-based LLMs, we now have huge models with Billions of parameters, which do not really require that kind of experimentation.
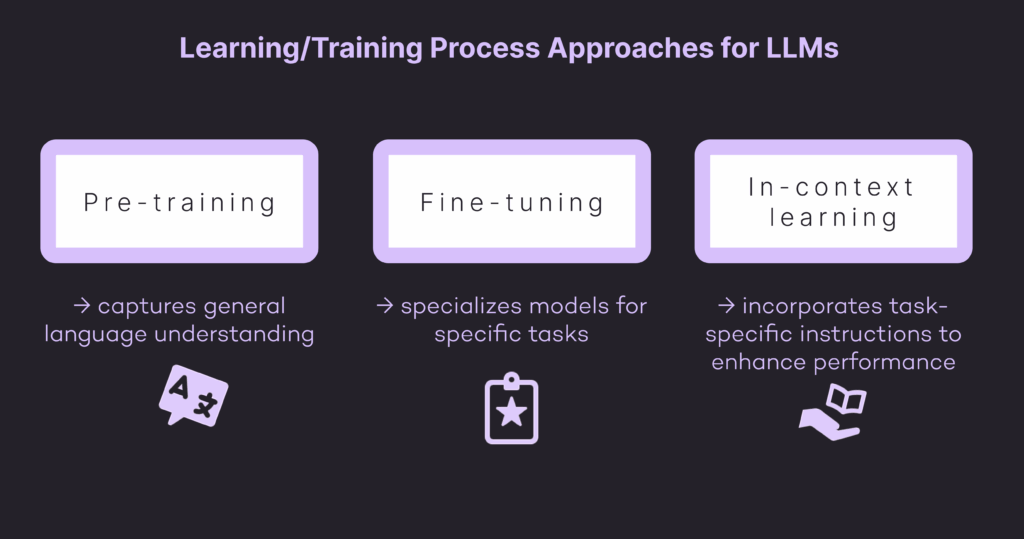
There, 3 primary approaches are used to work in the learning/training process of the large language models. Those are:
- Pre-training
- Fine-tuning
- In-context learning
Basically, Pre-training captures general language understanding, fine-tuning specializes models for specific tasks, and in-context learning incorporates task-specific instructions to enhance performance.
Source: Graphic by applydata.
Let’s dive into all these three approaches to better understand how they work. I present them with the order of accessibility, considering the required technical knowledge and computational resources.
What Is In-Context Learning?
LLMs have shown the capability to learn new skills and solve new tasks simply by providing new examples in the prompt (input). Also, without training the model, there is no gradient update or change in model parameters. This approach is called In-Context Learning. In-Context Learning is the ability to learn the context of the input and apply it to generate the correct output. This is one approach that can use large language models.
Explaining the model with unambiguous instructions on how to perform the tasks allows the model to better understand and perform the tasks more easily. Using these few examples is then competitive against training models with many more labelled data. This has led to the emergence of various strategies to exploit In-Context Learning, like prompt engineering, since changing the prompt allows for better performance than having to do fine-tuning for a specific task.
What is a prompt?
The prompt is the textual input that is given to the model to generate desired output. This textual input provides all the information and instructions that we want the model to consider.
What is Prompt Engineering?
This is the technique of composing and formatting the prompt to maximize a model’s output on a desired task. This has allowed us to interact with LLMs effectively via natural language. It involves carefully designing the initial input or question given to the LLM, which sets the context and guides the model’s response.
What is Retrieval Augmented Generation (RAG)?
RAG is a framework for building LLM-powered applications that make use of external data sources outside the model and enhance the input with data, providing a richer context to improve output. The RAG first runs the customer query with the corpus to fetch relevant specific information. Then, it passes the retrieved information to LLMs. Read more about RAG in my blog article From Simple to Advanced Retrieval Augmented Generation (RAG).
What Is Fine-tuning LLMs?
The second approach of using an LLM is model fine-tuning, which involves taking a pre-trained model and adjusting it for a specific use case by training at least one internal model parameter, such as weights and biases. In the context of LLMs, this typically results in transforming a general-purpose base model into a specialized model for a particular use case.
Benefits of fine-tuning LLMs
The main benefit of this approach is that models can achieve better performance while requiring fewer manually labelled examples than models that rely solely on supervised training. Fine-tuning not only improves the performance of a base model, but a smaller fine-tuned model can often outperform larger, more expensive models on the set of tasks for which it was trained.
LLMs have a limited context window. As a result, the model may not perform well on tasks that need a large knowledge base or domain-specific information. Fine-tuned models can avoid this issue by learning this information during the fine-tuning process. This also eliminates the need to stuff prompts with additional context, which can result in lower inference costs.
What Is Pre-training LLMs?
To comprehend which model to use for a certain task, it is crucial to understand the training process for large language models. This training process, often called pre-training, entails the model learning from a vast amount of unstructured textual data. Gigabytes, terabytes, or even petabytes of text are used, gathered from various sources like internet scrapes and curated corpora. While prompt engineering and model fine-tuning can likely handle 99% of LLM applications, there are cases where one must go even further.
Training objectives
During pre-training, the model’s parameters are adjusted to reduce the loss of the training objective. The training objective changes depending on the model architecture, such as masked language modelling for autoencoding models or causal language modelling for autoregressive models. The goal is for the model to develop a comprehensive statistical representation of language by internalizing the patterns and structures present in the data.
Large models
Larger models have better capabilities and performance. Studies have shown that as models grow in size, they are more likely to perform well without additional fine-tuning or training. Training these large models presents challenges and high costs, which may limit continued growth. Understanding the training process and the differences between autoencoding models, autoregressive models, and sequence-to-sequence models allows developers to choose the most appropriate model for their generative AI applications. More detailed information and tips for the training and tuning process I collected in my article Pre-training to Fine-tuning of LLMs.
Author info
