
In the rapidly evolving world of artificial intelligence, Machine Learning models are growing larger and more complex by the day, from billion-parameter language models to high-resolution computer vision systems. But they also demand immense computational power, memory, and energy. How can we shrink these models without compromising their accuracy?
This is where quantization would help us as a transformative technique that bridges the gap between cutting-edge AI and practical deployment by converting high-precision numbers into lower-precision formats. Quantization drastically reduces model size, accelerates inference speeds, and slashes power consumption. There is so much about quantization. In this blog post, we’ll explain what quantization is, what it does, and why it’s important. We’ll also cover topics such as post-training quantization, Quantization Aware Training (QAT), and popular libraries like GGML, GGUF, GPTQ, etc.
Let’s start with weights in neural networks.
Neural Network Model Weights
Weights are the parameters in a neural network that determine how the network learns and makes predictions. They are actually real numbers that are associated with each connection between neurones in the network. The weights allow the neural network to learn the relationships between input data and the desired output data.
By the way, if you want to refresh your basic knowledge about neural networks first, find an overview in our blog post about AI vs. Machine Learning vs. Deep Learning.
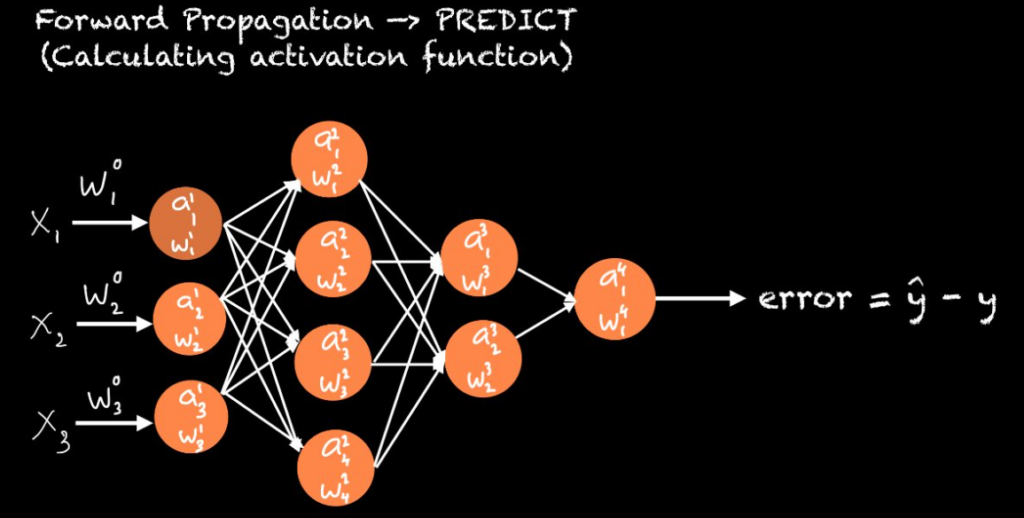
In a neural network, each neurone receives input from another neurone, and the input from each neurone is multiplied by the weight, and the sum of all the weighted inputs is then passed through an activation function. Then the activation function ultimately decides or determines whether the neurone will fire or not.
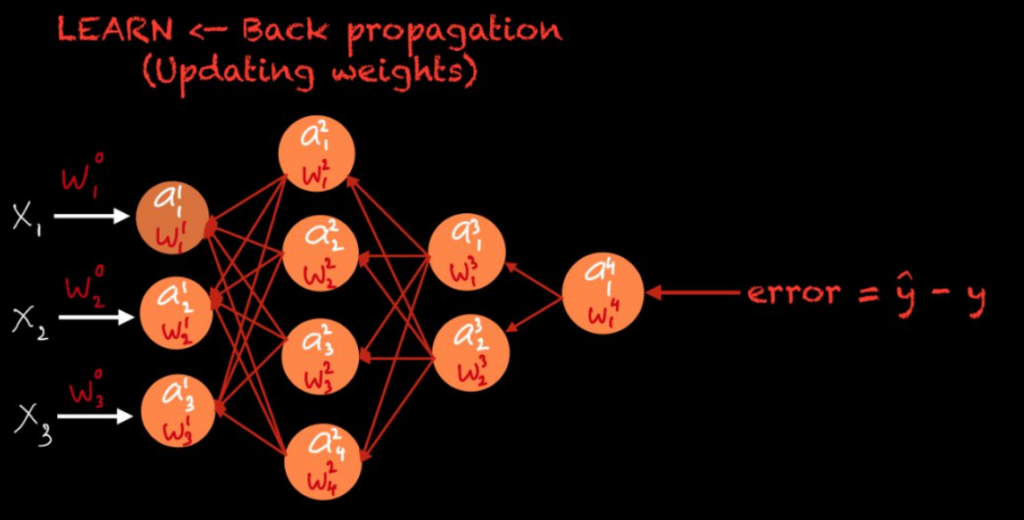
Initially, the weights are randomly initialized. But as the training process goes on, the weights are optimized and adjusted based on the optimization that we have selected. This is the foundation of a technique called back propagation. Back propagation lets you optimize and change the weights in such a way that you can minimize the error.
How Are Weights Related to Quantization?
Now, these weights are stored in the neural network; that’s what we call the model weight. These weights are stored in the neural network with different precisions. We could store these weights as a 32-bit floating point, or 16-bit floating point, or even 8-bit floating point or 8-bit integer, or 4-bit integer.
When we talk about a weight, we generally call it a number, but this number under the hood in computers could be of different precision and data types. Based on the data type or based on the precision, a lot of things changed including the amount of time this neural network takes for inference and the size of the neural network, ultimately the model in itself.
If we say Deep Learning model, the model is nothing but a neural network with its weights. A neural network is a bunch of numbers stored here and there, and its matrix multiplication numbers are stored in the form of weights, biases, and activations. When these numbers are stored with a higher precision floating point like a 32-bit floating point, these models take a lot of space and require more computation when the models have to predict, which we also call inference.
The model is going to be huge when the weights are stored in a higher precision. More precision means more accurate number representation of that floating point value, but the model’s weight decreases as you reduce the precision. That is where a very interesting technique comes in: quantization.
What Is Quantization?
Quantization in neural networks is the process of reducing the precision of the weights, biases, and activations of a neural network in order to reduce the size and computational requirements of the model. This can be done without significantly impacting the accuracy of the model in many cases.
Quantization happens at two different places:
- Post-training quantization
- Quantization Aware Training
What we do mostly with GGML, GGUF, and GPTQ models is post-training quantization.
What Is Post-Training Quantization?
Post-training quantization is the process of quantizing a pre-trained neural network. (I already wrote an article about Pre-training to Fine-tuning of LLMs if you want to explore this specific topic further). This can be simply done by a rounding of weights or activation to a lower precision, but this can also lead to some kind of loss in accuracy. In the post-training quantization, you might take a model that has a floating point 16 precision, and you can convert it into a 4-bit or 8-bit integer.
By doing this, you are quantizing the model in such a way that the weight of the model reduces, the size of the model reduces, and it also improves the performance of the model in terms of the hardware that is required to run it. Which is also improving the model more performant in lower computation, and the model is also going to require less compute power for matrix multiplication. This can also lead to accuracy loss. Now, with all these things in mind, the two popular model types in post-trained quantized models are GGML and GPTQ models.
GGML, GGUF, GPTQ, AWQ and EXL2 models are quantized models and a way to reduce the models and to reduce the computation requirements of the model by reducing the model weights to a lower precision.
GGML
GGML was a high-performance tensor library, also an early attempt at making a file format for OpenAI’s GPT models to facilitate the easy sharing and running of models. GGML was the file format that directly preceded GGUF and was developed by Georgi Gerganov. The name is a combination of Gerganov’s initials (GG) and ML for Machine Learning. It aimed to make LLMs accessible on standard hardware.
GGML supports various quantization formats, including 16-bit float and integer quantization (4-bit, 5-bit, 8-bit, etc.), while reducing memory footprint and computational cost of models. This is also optimised for Apple M1 and M2 processors and x86 architectures. GGML is fast, portable, and easily embeddable and is written in C/C++. It doesn’t require a specific model file format, allowing conversion from any framework (like TensorFlow, Pytorch, etc.) to a binary file for easy handling.
GGUF
GGUF is a file format designed to store models for inference using GGML and executors based on GGML. It was introduced as a successor to GGML. GGUF offers improvements as a binary format optimized for speed and ease of use when loading, saving, and reading models. Models were built using PyTorch or another framework and then converted to GGUF for use in GGML.
While GGML was a valuable initial effort, GGUF addresses its limitations and represents an advancement in language model file formats. GGUF aims to overcome GGML’s shortcomings and enhance the user experience by providing more data about the model, making it easier to support multiple architectures. Notably, both GGUF and GGML leverage the CPU for running LLMs but also offload some of its layers to the GPU, taking advantage of your GPU to speed up the process.
GPTQ
Generative Post-Trained Quantization (GPTQ) is a library that leverages the GPU to quantize the precision of the model weights. GPTQ files can reduce the original model’s size by a factor of four. This GPU-optimized format is often the best choice if you have a compatible graphics card. GPTQ is popular because it’s designed for efficient GPU utilization. The underlying concept is to compress all weights to a 4-bit quantization by minimising the mean squared error to that weight. During inference, it dynamically dequantizes its weights to float16 to enhance performance while maintaining low memory usage.
It is definitely worth starting with GPTQ and switching over to a CPU-focused method like GGUF if your GPU cannot handle such large models.
AWQ
Activation-aware Weight Quantization is also a quantization method similar to GPTQ. There are several differences between AWQ and GPTQ as methods, but the most significant one is that AWQ assumes that not all weights are equally important for an LLM’s performance. In other words, a small fraction of weights will be skipped during quantization, which helps reduce quantization loss. Consequently, their paper mentions a substantial speed-up compared to GPTQ while maintaining comparable and sometimes even superior performance.
EXL2
ExLlamaV2 is an inference library designed to run local LLMs on modern consumer GPUs. It is an optimized quantization approach which aims to enhance both inference speed and computational efficiency. While less prevalent compared to methods like GPTQ, EXL2 aims to minimise latency during inference by optimizing weight quantization and activation functions. This library is particularly beneficial in deployments where quick responses are paramount, such as real-time applications.
What Is Quantization Aware Training (QAT)?
We can begin Quantization Aware Training with either a pre-trained model or a Post Training Quantized (PTQ) model. We then fine-tune this model using QAT. The objective here is to recover the accuracy loss that occurred due to PTQ if we had used a PTQ model. The forward pass is affected by QAT, while the backward pass remains unaffected. In Quantization Aware Training, quantization is performed for layers that do not result in excess loss in accuracy when their parameters are quantized. Conversely, layers whose quantization reduces accuracy are left unquantized.
The fundamental concept of QAT is to quantize the input into lower precision based on the weight precision of that layer. QAT also ensures that the output of the multiplication of weights and the inputs are converted back to higher precision if the next layer requires it. This process of converting input to lower precision and then converting the output of weights and inputs back to higher precision is also known as “FakeQuant Node Insertion”. The term “Fake” is used because it quantizes and then dequantizes, effectively converting to the base operation.
The model’s learning process
QAT introduces quantization error in the forward pass, which accumulates to the error and is then tuned using an optimizer in the backward pass. This way, the model learns how to optimise itself by reducing the error introduced by quantization.
Weights are the parameters in a neural network that govern how it learns and makes predictions. Each weight is a real number associated with a connection between neurons in the network. By adjusting these weights during training, the neural network learns the relationships between input data and the desired output.
Quantization in neural networks is the process of reducing the precision of a network’s weights, biases, and activations to decrease the model’s size and computational requirements. In many cases, this can be done without significantly affecting the model’s accuracy. Quantization can be applied in two ways: post-training quantization and quantization-aware training (QAT).
Quantization Aware Training (QAT) fine-tunes a pre-trained or post-training quantized model to recover any accuracy lost during quantization. During QAT, inputs and weights are temporarily quantized in the forward pass, while the backward pass remains in full precision, and layers that would lose too much accuracy remain unquantized. This process, often called “FakeQuant Node Insertion,” simulates lower-precision computation while preserving overall model accuracy.
Author info
