
In this post, we are going to explore another method of making our ML model more efficient called “knowledge distillation”. Imagine teaching a complex subject by simplifying the key concepts, allowing a student to grasp the essence without needing to memorize every intricate detail. That’s essentially what knowledge distillation does in the world of machine learning, transferring the “wisdom” of a large, powerful model to a smaller, more manageable one.
What Is Knowledge Distillation?
Knowledge distillation, also called Model distillation, refers to the process of transferring knowledge from a larger model to a smaller model. The larger, often more complex model is referred to as the teacher, and the smaller, more efficient model is referred to as a student. When we talk about larger and smaller models, we are measuring model size in terms of parameters.
In knowledge distillation, we first use the data to train a teacher model, or we can also use an already trained model as the teacher model. After the teacher model has been trained, we start training the student model to predict the outputs of the teacher model.
The concept of knowledge distillation was first introduced by Jeffrey Hinton, Oriol Vinyals and Jeff Dean in their paper titled ‘Distilling the Knowledge in a Neural Network’ presented in 2015.
What Is the Goal of Distillation?
The goal is to maintain the smaller model’s performance as close as possible to the teacher model while significantly reducing the computational resources required for inference and deployment.
How Does It Work?
Training a smaller student model using knowledge from a teacher model involves several key steps.
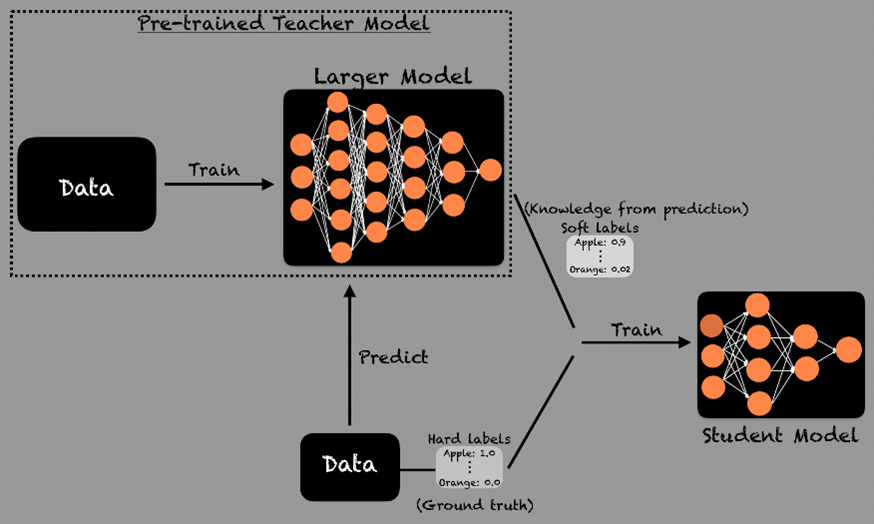
First, the teacher model generates soft labels. We then start training the student model to predict the outputs of the teacher model. In addition to the training with soft labels, the student model learns from the ground truth as well. Both of these steps help the student model capture the reasoning patterns of the teacher rather than just memorizing correct answers. Once a student model learns from the teacher model, it can be fine-tuned further on task-specific data sets. This helps to ensure the student model performs well in real-world applications, even if it’s much smaller than the teacher model.
What Are Soft Labels?
Instead of just giving correct answers, the teacher model outputs the probability distributions over possible answers. Assuming you’re doing some kind of classification model, then the training data has only one label per training instance, but the output of the teaching model gives you a probability distribution over all possible labels, which is a lot more information to learn from. For example, instead of just saying “apple”, the teacher model might say “apple” with 90% probability, “peach” with 5% probability, “pears” with 3% probability, or “orange” with 2% probability.
These soft labels help the student model to understand confidence levels rather than just right and wrong answers. As the output of the teacher model contains more information, it is faster and easier for the student model to learn from it.
Why Use Knowledge Distillation in LLMs?
One big reason is efficiency. Smaller LLMs require less computational power, making them suitable for mobile or edge devices or other low-latency applications such as real-time translation or summarization. With better efficiency, you reach cost savings, and reduced resource consumption leads to lower inference in operational costs. Additionally, with more efficiency, you can scale up to more users and tasks with comparatively less infrastructure.
Another advantage of knowledge distillation in LLMs is that you can modify the architecture of the student model to be different from the teacher model. For example, if the teacher model has 12 transformer layers, that doesn’t mean that the student model has to have 12 transformer layers; it might have 6 or 2 or something like that. And this sort of architectural change is not really possible with Quantization in AI. Therefore, knowledge distillation has the biggest potential gain in speed compared to all of the other methods that we have seen.
What Are the Challenges of Knowledge Distillation?
The first is loss of information. A smaller model might not fully capture the nuances of the larger teacher model. The second challenge is ensuring the distilled model generalizes well across diverse tasks or domains.
Another disadvantage is that it is relatively more difficult to set it up, because you need to set up the training data, which might be billions of tokens, and if the teacher model is a big model, then running inference over it can be a challenge. So, overall, knowledge distillation is relatively expensive. Practically, this takes maybe 5-10% of the total compute or GPU hours needed to train the teacher model from scratch.
Here is one example: DistilBERT is a model trained with knowledge distillation where BERT is a teacher model.

Source: https://arxiv.org/pdf/1910.01108
In this model, they reduced the size of the BERT-based model by 40% while retaining 97% of its accuracy. The authors tell us how many GPUs and for how long they had to train this model. DistilBERT was trained on 8 GPUs for about 90 hours, so in total, about 700 hours of GPU time. In comparison, the RoBERTa model, which is similar to the BERT model, required one day of training on 1,000 GPUs, which is about 24,000 hours of GPU time, or around 20 times more.
So, in this DistilBERT example, training our model using knowledge distillation is a lot faster than training from scratch, but it still requires a significant amount of compute.
What Are some Examples of Distilled Models out in the Real World?
The first is DistilBERT, which was distilled from BERT, developed by Google. DistilBERT is 40% smaller, 60% faster, and still retains 97% of BERT’s performance. Another distilled model is DistilGPT-2, which was distilled from GPT-2, developed by OpenAI. DistilGPT-2 is between 35-40% smaller, 1.5x faster and still retains 95-97% of GPT-2’s performance.
DeepSeek recently introduced six models distilled from DeepSeek-R1, which are based on Qwen and Llama, delivering impressive results. According to their findings, the distilled Qwen-14B model significantly outperforms the state-of-the-art open-source QwQ-32 B-Preview. Additionally, the distilled Qwen-32B and Llama-70B models have achieved record-breaking performance on reasoning benchmarks among dense models.
Outlook
In summary, knowledge distillation in LLMs will be popular because it significantly reduces compute costs, speeds up inference, and enables real-time AI on mobile, edge and cloud environments while retaining most of the accuracy of large models. As AI adoption scales, businesses as well as developers will prioritize efficient, affordable, and scalable models to power applications without the need for massive infrastructure.
Author info
