
Data and AI engineering form the foundation for how organisations build, scale, and operationalise intelligent systems: from data ingestion and architecture to model deployment. Expectations around automation, speed, and AI-driven decision-making continue to rise, letting engineering teams face tricky challenges around:
>>> Which platforms should we choose when the options are increasing rapidly?
>>> Which data should be used, and when?
>>> How can we maintain governance over these complex systems?
For this article, we hand-picked five data and AI engineering trends for 2026 that look promising, offer food for thought, or can be discussed critically. Ready for (some of) this year’s big players in data & AI?
1. Multimodal Lakehouses
In mid-2025, LanceDB introduced the Multimodal Lakehouse suite into its enterprise offering, widely spreading the term “multimodal lakehouse” online. We all heard of data lakes, storing different kinds of raw data in a central location. So-called multimodal lakehouses unify storage and retrieval of even more complex data types such as video, audio, 3D models, and embeddings into a single system. Here, the system is designed for AI-native workflows such as Retrieval-Augmented Generation (RAG) and model training pipelines.
By the way: if you want to refresh your knowledge about RAG, I can highly recommend reading my colleague’s article about “From Simple to Advanced Retrieval Augmented Generation (RAG)”.
A key difference compared to traditional data lakes is how these systems treat media and vector data. Rather than storing them as secondary or auxiliary files, multimodal lakehouses handle them as core data. Vector search is embedded directly into the storage engine, removing the need for external indexing and enabling hybrid queries like “find similar audio snippets from the last hour”.
Benefits of multimodal lakehouses
- reduced latency, because zero-copy pipelines allow training and serving from the same raw data without duplication
- streaming updates make it suitable for dynamic production environments: they enable deployed models and dashboards to react instantly to new data, ensuring predictions and insights stay current without manual data reloads (while retraining can be automated if required)
- low operational overhead & faster time-to-market: the multimodal lakehouse provides AI engineers with streamlined access to computing and data tools, allowing them to focus more on creative tasks such as development and experimentation rather than data infrastructure
Use case of multimodal lakehouses
- recommender systems: derive vector representations from user behaviour data, such as logs and clicks, to enable nearest-neighbour retrieval
- LLM & AI model training: prepare large text collections by extracting, cleaning, and embedding data for use in transformer models & AI model training with mixed data types
- semantic search engines: create hybrid search workflows that combine embeddings with captions, thumbnails, and structured metadata
But: centralized, efficient data management becomes even more critical if multimodal AI systems spread in 2026.
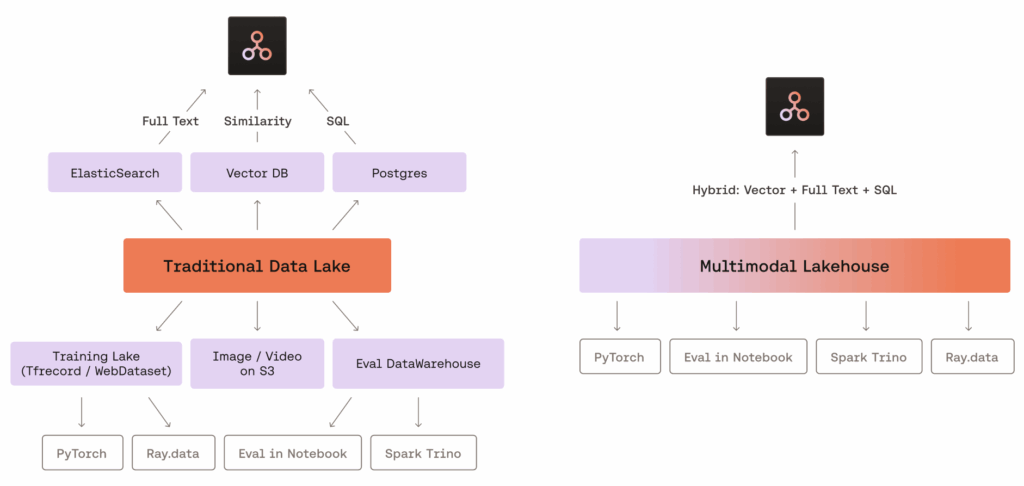
Graphic source: LanceDB (https://lancedb.com/blog/multimodal-lakehouse/?utm_source=gradientflow&utm_medium=newsletter)
2. Evaluation-Driven Development (EDD)
Another trend that speaks directly to all the data-lovers in the world: Evaluation-Driven Development, or EDD for short. This approach makes evaluation tests, also called “eval” tests, the core of AI and data development, going beyond traditional unit testing.
So, what makes Evaluation-Driven Development different?
- end-to-end focus: evals act like end-to-end tests for AI and probabilistic systems, assessing output quality rather than individual code paths
- flexible assessment: they combine automated checks, human judgment, and AI-assisted grading to account for inherent variability in AI outputs
- continuous improvement: by integrating benchmarking, trend analysis, and real user feedback, EDD guides data-driven system enhancement
In AI development, trade-offs are quite common: improving one metric can degrade another. Here, EDD can shine and help navigate these trade-offs scientifically: similar to a scientific method, you start with a hypothesis about expected behavior. Experiments and systematic evaluation confirm, refute, or refine your assumptions. This approach prevents AI projects from stagnating in the Proof-of-Concept limbo stage (being successful in theory but never delivering real-world value) and promotes iterative, measurable progress.
In short, EDD helps productionize and improve ideas iteratively. In the practice of EDD, models are refined based on systematic evaluation, not just raw training data. For example, an LLM can act as a “judge” to rate the relevance of semantic search results on a scale from 0 to 3, and these ratings can then guide model improvements in an iterative loop.
Key benefits of Evaluation-Driven Development (EDD)
- traceability and reproducibility: versioned evaluation suites in CI/CD pipelines make system changes trackable and block regressions
- trend analysis: teams can monitor performance across multiple runs, rather than relying on single snapshots
- robust quality control: especially critical for complex systems like LLMs, RAG pipelines, AI agents, and large Agentic AI systems
So, for teams working with modern AI applications, EDD is rapidly becoming a best practice for measurable, high-quality outcomes. And so the decisions in the development phase can move away from intuition-based trial-and-error prompt engineering, focusing on quick wins. Or as Dr. Nimrod Busany, leader of the Knowledge Engineering & AI Labs at Tel-Hai University, formulates it quite on point in his blog article: “The age of “YOLO prompt engineering” is ending. The age of “statistically validated, continuously evaluated, cost-optimized AI systems” has begun.”
3. AI-Native Data Platforms
AI-native platforms become essential for building efficient, intelligent AI applications. But what actually makes a data platform AI-native? These platforms can shift the focus from raw data processing to semantic understanding within a business context. They are designed to handle both structured and unstructured data, including high-dimensional vector embeddings used for similarity search and semantic retrieval. To make this scalable and fast, AI-native data platforms rely on advanced indexing techniques such as Approximate Nearest Neighbour (ANN), combined with GPU acceleration for fast, scalable query execution.
Hybrid queries are a great capability as well: combining vector-based similarity search with structured filters enables context-aware, precise results. Therefore, with semantic queries gaining importance and data volumes growing continuously, AI-native data platforms are a/the way to go.
Benefits of AI-native data platforms
So what are the concrete benefits of AI-native data platforms? AI-native data platforms significantly simplify system architectures by consolidating capabilities that previously required multiple specialised tools. At the same time, they enable real-time analytical insights by embedding AI capabilities directly within the database, making it easy to run machine learning tasks and Retrieval-Augmented Generation (RAG) workflows.
AI-native data platform use cases
Among many other examples, AI-native data platforms shine in:
- enabling seamless customer experience & personalisation: personalised product & content recommendations, dynamic pricing, conversational analytics for customer support and sales assistants (the topic of AI-supported sales assistants sparks your interest? Then check out NEVO)
- risk, security & compliance: fraud detection, credit scoring, real-time risk assessments
- operations & supply chain: inventory forecasting, logistics route optimisation
4. Context Engineering for LLMs
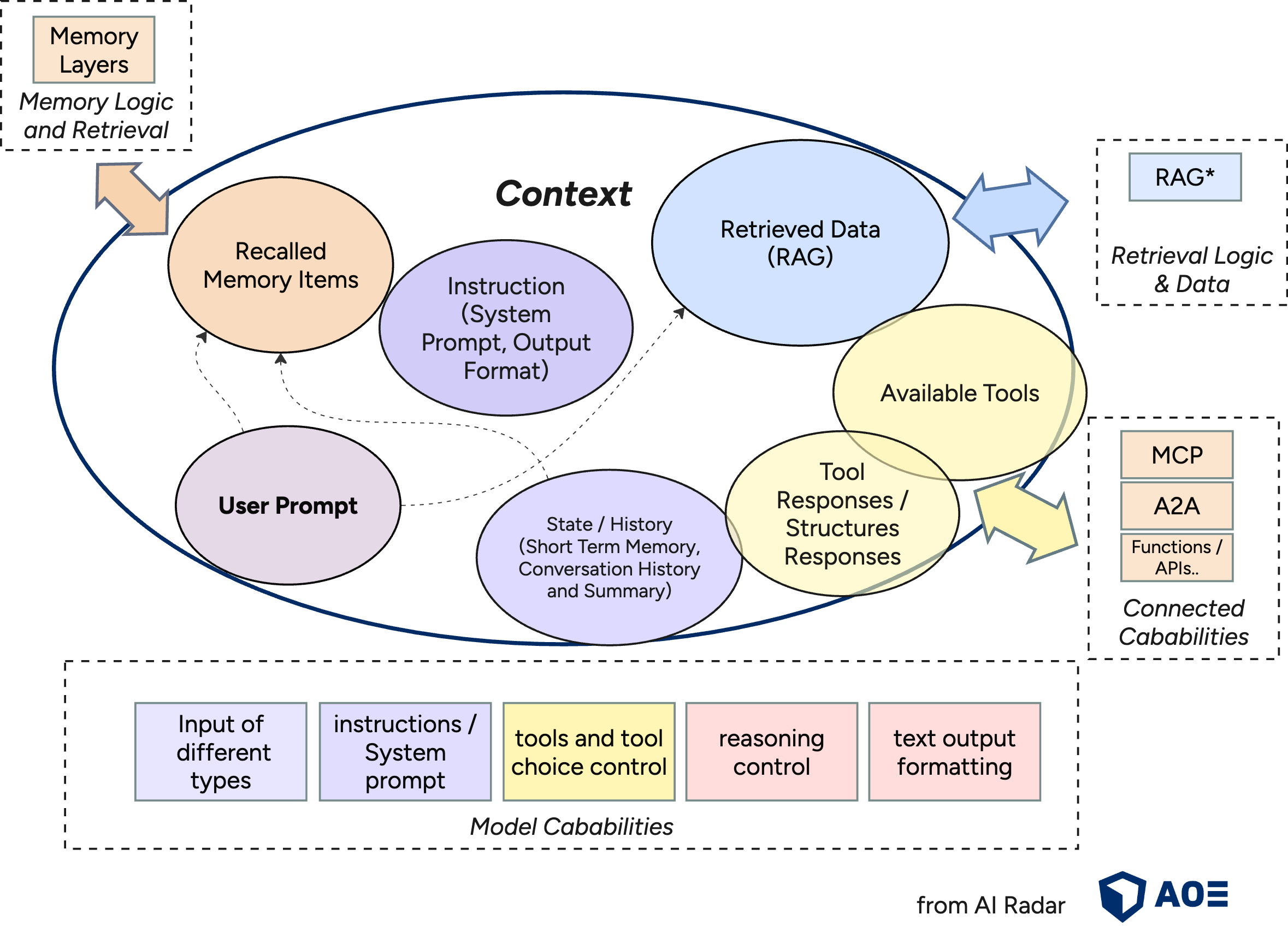
Do you know those LinkedIn posts where people complain about funny, but unusuable ChatGPT answers, and then there’s always one person in the comments saying, “it’s because you didn’t give it any context…”? You can think of that as the simplest (and often failed) version of context engineering. At its core, the engineering challenge is about deciding what information goes into a model’s limited context window (the maximum number of tokens that an LLM can process simultaneously), and how to structure that information so you consistently get the desired outcome.
In practice, successfully working with LLMs means thinking in terms of context as the full set of information available to the model at any moment (system instructions, conversation history, retrieved documents, user data, tool outputs,…) and the behaviours that combination is likely to produce.
What’s the difference between prompt engineering and context engineering?
The trend of context engineering represents a more advanced approach, and it takes a look at the full spectrum of what “context” can mean. But let’s first clarify exactly what context engineering is and how it differs from prompt engineering, which has dominated AI discussions in recent years: prompt engineering focuses on crafting instructions, whereas context engineering designs the entire input ecosystem. In other words, a prompt is just one part of context. For a more detailed comparison between prompt and context engineering, see this article by Anthropic.
What are the benefits of context engineering for LLMs?
The objective of context engineering is to maximise output relevance within limited context windows while minimising latency and ensuring reliability. That means that proper context engineering can directly impact the cost, performance, and reliability of AI systems. Context engineering optimises the full information landscape that an LLM can access during inference: prompts, memory, retrieved data, current conversation state, and tool outputs. For doing so, it leverages different techniques, such as chunking, retrieval routing, memory management, or structured API calls. In the end, it’s about designing systems that ensure an LLM receives exactly the information and tools it needs, properly structured and at the right moment, to successfully perform a task.
What an LLM produces is shaped primarily by the context it receives: the information provided, its structure, its relative importance. In real-world agentic systems or RAG pipelines, strong context engineering heavily supports turning experimental prototypes into scalable systems.
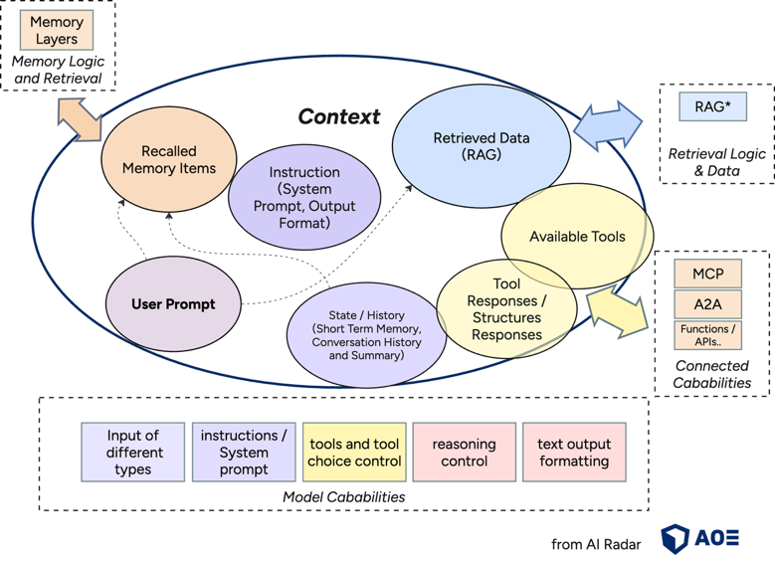
Graphic source: AOE AI Radar (https://ai-radar.aoe.com/images/context-engineering.png)
{kind=link}
5. Synthetic Data Generation (SDG)
For proper model training, you need a good amount of data. Sometimes VAST amounts. But what happens if you don’t have enough high-quality data available? That’s where synthetic data comes into play. Synthetic data is artificially generated data that can take many forms: text, images, videos, tabular data, and more, both structured and unstructured. It is created using rules, algorithms, or simulations that mimic the statistical properties of real-world data, making it useful for training, validating, and testing models.
How to generate synthetic data?
Synthetic data can be generated using computer simulations, mathematical models, or generative AI systems. For example, NVIDIA’s Nemotron‑4 340B is a family of generative models that developers can use to produce synthetic text-based data for training large language models (LLMs). Similarly, methods such as GANs (Generative Adversarial Networks) can generate realistic images, while simulation software can create synthetic sensor or IoT data for autonomous vehicles. The generation process can be carefully controlled to produce balanced, diverse, and realistic datasets that reflect the properties of real-world data, while significantly reducing the risk of copying or exposing sensitive information.
When is synthetic data generation (SDG) useful?
Synthetic data is useful across many domains, especially when real-world data is:
- limited (data scarcity)
→ For example, medical imaging datasets for rare diseases are often too small to train effective AI models. Synthetic images can augment these datasets. - imbalanced or not very representative
→ Training models on datasets with skewed class distributions can produce biased outputs. Synthetic data can fill gaps, for example, for generating more examples of underrepresented categories in credit risk datasets. - difficult to use because of its sensitivity (think of data privacy/protection standards)
→ Certain data, like financial transactions, legal records, or patient health information, is highly regulated. Synthetic data can replicate patterns from these datasets without exposing personal information, making it safe for training and sharing.
In such cases, generating and using synthetic data allows teams to build high-quality, diverse datasets that improve model performance, reduce the time needed to gather real-world data, and speed up the AI development process.
Synthetic data generation (SDG) for Evaluation-Driven Development (EDD)
It is also particularly helpful in supporting the aforementioned Evaluation-Driven Development (EDD): synthetic datasets can serve as controlled, high-quality evaluation sets to test model performance under different scenarios to identify weaknesses and iterate quickly based on the gathered information. For example, a synthetic customer support dataset can be used to evaluate how an AI chatbot handles rare or complex queries without exposing real customer conversations.
Final Thoughts on Our 5 Data & AI Engineering Trends in 2026
We’ve introduced you to our 5 Data & AI Engineering Trends in 2026: Multimodal Lakehouses, Evaluation-Driven Development (EDD), AI-Native Data Platforms, Context Engineering for LLMs and Synthetic Data Generation (SDG). The more technologies evolve, the harder it is to stay focused on a few of them to actually move projects and products forward and not get lost in all the shiny opportunities. Now it’s your time to ask yourself, which ones do you perceive as nice to have or as an exciting trend you want to integrate soon? And which ones do you really perceive to stay long-term…?
Author info
