
Datenmanagement ist die Praxis einer Organisation, ihre Daten zu sammeln, zu speichern, zu verarbeiten und zu sichern, mit dem Ziel, den Wert der Datennutzung für alle verschiedenen Geschäftsprozesse zu maximieren. Erfahre, wie du dein Unternehmen zukunftssicher machen kannst, indem du die bedeutendsten Datenmanagement-Trends nutzt.
In diesem Artikel überprüfen wir 5 der disruptivsten Trends, die wir in unserer Praxis identifiziert haben, um die digitale Transformation in Organisationen voranzutreiben.
1. Automatisierung und KI
Um mit der Datenexplosion umzugehen, setzen immer mehr Unternehmen auf generative KI. Künstliche Intelligenzlösungen gestalten die Zukunft der Business Intelligence, indem sie menschliche Einsichten und Ausführungen verbessern.
Ein beliebtes Anwendungsbeispiel ist die Sentimentanalyse. Das ist eine Technik, die eine Mischung aus natürlicher Sprachverarbeitung, Linguistik, Textanalyse und Algorithmik nutzt, um die emotionale Aufladung von user-generated Texten im Internet zu erkennen. Monitoring-Tools für soziale Medien haben diese Gelegenheit genutzt, um Produkte zu entwickeln, die Emotionen in Online-Communities analysieren und informieren, um fundierte Kommunikationsstrategien zu unterstützen.
Eigene Anwendungen entwickeln
Das Gute daran, im digitalen Zeitalters zu leben, ist, dass Organisationen nicht auf das abgeschottete System eines Anbieters beschränkt sind. Heutzutage können Unternehmen ihre eigenen Anwendungen für internen Gebrauch mit Open-Source-Tools wie der Google Cloud Natural Language API entwickeln.
Mit Google BigQuery haben technische Teams alle notwendigen Werkzeuge, um ein kosteneffizientes Datenprodukt zu entwickeln. Darüber hinaus können sie in Looker Studio (ehemals bekannt als Data Studio) – einem kostenlosen Visualisierungstool von Google – ein Dashboard erstellen, das eine benutzerfreundliche Oberfläche bietet, damit andere Teams die Daten nutzen können.
ChatGPT im Einsatz
Eine weitere bekannte Nutzung von Künstlicher Intelligenz ist niemand anderes als ChatGPT, der Chatbot, der von OpenAI trainiert wurde und in letzter Zeit in aller Munde ist. Seine Anwendungsfälle reichen von der Erstellung von Blogbeiträgen bis hin zur Lösung von Programmierproblemen. Obwohl die Resonanz überwiegend positiv ist und das KI-Modell die Zukunft der Arbeit und Technologie revolutionieren soll, kann es noch lange dauern, bis Künstliche Intelligenz allgemein umgesetzt wird. Diejenigen, die KI annehmen und nach und nach in ihre Organisationen integrieren, werden zweifellos den Wettbewerbsvorteil der Erstanwender ernten, während sich die Technologie weiterentwickelt.
Schau dir ChatGPT in Aktion an:
2. Edge Analytics
Kaum haben digitale Organisationen effiziente Datenmanagementsysteme für ‚traditionelle‘ Datenquellen entworfen, stehen sie bereits vor einer neuen Herausforderung. Der Aufstieg vernetzter Geräte und IoT-Systeme erfordert neue Strategien, bei denen Echtzeitverarbeitung von entscheidender Bedeutung ist.
Einblicke in unsere Arbeit bei diconium data
In unserer langjährigen Geschichte im Mobilitätssektor haben wir Edge Analytics für mehrere Projekte genutzt, von denen wir glauben, dass zwei besonders hervorstechen. Obwohl wir uns der Privatsphäre unserer Kunden bewusst sind (übrigens, ich könnte einen ganzen Artikel den Trends im sicheren Datenmanagement widmen), möchten wir einen kurzen Überblick darüber geben, wie wir am Edge mit Daten umgehen.
Fahrzeugdaten
In Zusammenarbeit mit einem deutschen Automobilhersteller in den Monaten vor der Veröffentlichung ihres E-Automodells entwickelten unsere Kollegen eine App, die sich nahtlos mit Ladestationen integriert. Die Lösung ermöglicht es Autobesitzern, auf Daten von Ladestationen am Edge zuzugreifen und ihre Reisen im Voraus mit voller Vorhersehbarkeit in Bezug auf Anbieter, Standorte, Verbindungen und mehr zu planen.
Monetarisierung von Daten
Für das zweite Projekt arbeiteten wir mit einem B2B-Automobilunternehmen zusammen, das enorme Mengen an Sensordatenpunkten sammelt. Unsere Aufgabe war es, das finanzielle Potenzial ihrer Datenbestände zu ermitteln, was uns zu einem kritischen Punkt in der Diskussion über Datenkapital bringt – die Monetarisierung. Da alle Unternehmen im Geldgeschäft tätig sind, kann Edge Analytics wertvolle Monetarisierungsquellen für Unternehmen liefern, die ihre Einnahmequellen diversifizieren möchten.
3. Der Aufstieg von DataOps
DataOps ist eine Reihe von Praktiken innerhalb eines kollaborativen Datenmanagementmodells, das darauf abzielt, die Lücke zwischen Domain-Datenbesitzern und Datennutzern zu schließen. Um den Wert von Daten zu liefern, müssen Organisationen die Nutzung von Analysen beschleunigen und datengetriebene Entscheidungsfindung ermöglichen.
Warum DevOps?
In den Fußstapfen von Methoden wie DevOps und DevSecOps kommen DataOps-Teams zusammen, um die Geschwindigkeit der Analysen im Unternehmen zu beschleunigen und in umsetzbare Business Intelligence zu übersetzen. Die Methodologie von DevOps wird mit Datenspezialisten wie Dateningenieuren und Datenwissenschaftlern erweitert. Das Ziel ist es, Datenströme und die kontinuierliche Nutzung von Daten im gesamten Unternehmen zu ermöglichen.
In einem Bericht von Seagate US aus dem Jahr 2020 wurde festgestellt, dass durchschnittlich 10% der befragten Unternehmen DataOps unternehmensweit eingesetzt haben.
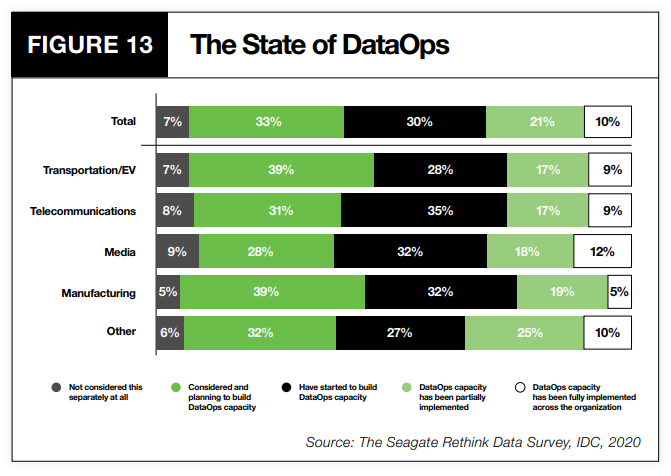
https://www.seagate.com/content/dam/seagate/migrated-assets/www-content/our-story/rethink-data/files/Rethink_Data_Report_2020.pdf
Im Gegensatz dazu finden satte 89% der Befragten, dass DataOps eine wichtige Rolle in ihrem Unternehmen spielten.
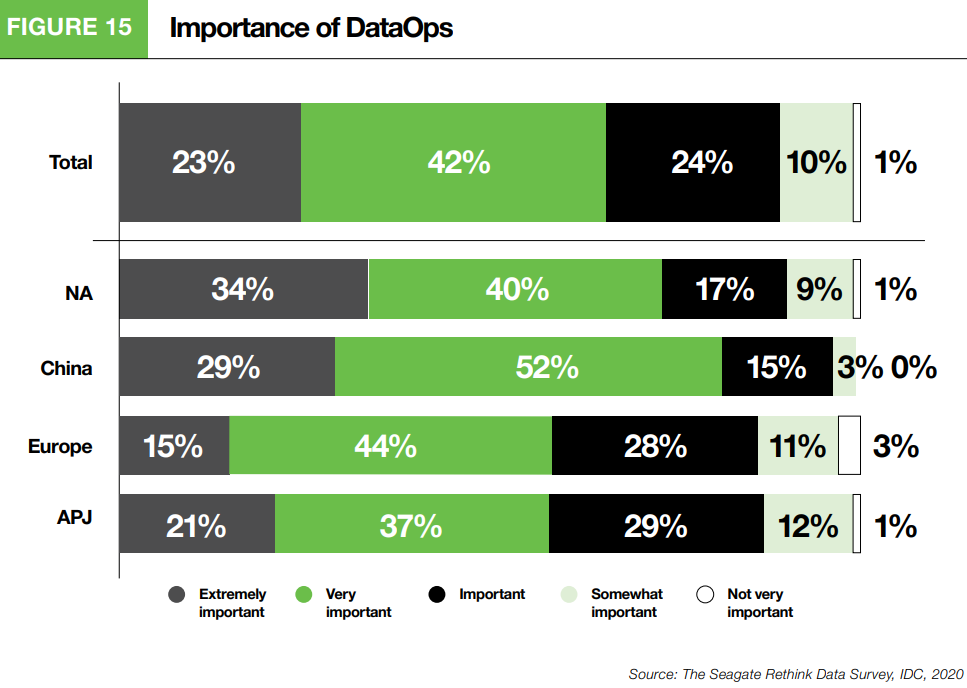
https://www.seagate.com/content/dam/seagate/migrated-assets/www-content/our-story/rethink-data/files/Rethink_Data_Report_2020.pdf
Die Ergebnisse deuten darauf hin, dass ein enormes ungenutztes Potenzial für Unternehmen besteht, in DataOps-Teams zu investieren und die Wertschöpfung aus ihren Daten zu verbessern, um so einen Wettbewerbsvorteil zu erlangen.
4. Eine Dateninfrastruktur zum Selbstbedienen
Der Wechsel zu einem Selbstbedienungs-Setup anstelle der Abhängigkeit von zentraler Datenverfügbarkeit ermöglicht es Teams, unabhängig zu arbeiten. Dies führt zu einer schnelleren Markteinführung und ist besonders relevant für große Unternehmen, in denen nicht jeder weiß, wer für was verantwortlich ist. Viele der Hindernisse, die in traditionellen Organisationen auftreten, werden so beseitigt, was zu erhöhter Effizienz und Selbstständigkeit führt.
Ein Beispiel für wertvolle Ressourcen, auf die Teams in einer Selbstbedienungs-Infrastruktur zugreifen können, sind Kataloge von Datensätzen. Du kannst dir diese wie interne Datenrepositorien vorstellen, die von allen relevanten Teams abgefragt und/oder für ihre Arbeit genutzt werden können. Dezentrale Teams innerhalb der Organisation sind nicht mehr auf ein zentrales Analytik-Team mit begrenzten Ressourcen angewiesen.
Unabhängigkeit und Effizienz in der Entwicklung von Datenprodukten
Eine Selbstbedienungs-Dateninfrastruktur ist eine Voraussetzung für Domain-Teams, die notwendige Unabhängigkeit zu erreichen, um ihre jeweiligen Datenprodukte zu entwickeln und zu besitzen. Organisationen, die nachhaltig skalieren und das volle Potenzial ihrer Business Intelligence ausschöpfen möchten, müssen Schritte unternehmen, um Engpässe zu beseitigen und die Zeit bis zur Wertschöpfung für ihre Daten zu beschleunigen.
Gestaltung einer inklusiven Dateninfrastruktur für alle Qualifikationsniveaus
Es reicht jedoch nicht aus, einfach die Verantwortung für Datenbesitz und -wartung zu dezentralisieren. Die unternehmensweite Dateninfrastruktur muss verschiedene Kompetenz- und Technologiegrade berücksichtigen, indem sie eine gemeinsame Plattform und Werkzeuge bereitstellt, die auch nicht-technische Geschäftsteams leicht verstehen können.
Daten-Mesh-Prinzipien
Als dezentrale Organisation sind wir bestrebt, immer auf dem neuesten Stand der Datenmanagement-Trends zu bleiben, während wir ihnen mit einem kritischen Auge begegnen. Das gesagt, sind wir große Fans der von Data Mesh vorgeschlagenen Prinzipien. Für alle, die in diesem Bereich tätig sind, sollte es nicht überraschend sein, dass die Selbstbedienungs-Dateninfrastruktur es in unsere Top 5 Datenmanagement-Trends für 2023 geschafft hat. (Wenn du erfahren möchtest, was ein Data Mesh ist, schau dir den Artikel an, den mein Kollege geschrieben hat.)
5. Data Fabric – Der aufstrebende Trend im Datenmanagement
Vereinzelte Datensilos belasten Unternehmen, behindern Innovationen und verschaffen digital versierteren Wettbewerbern einen Vorteil. Data-Fabric-Technologien kommen zum Einsatz, um solche Mängel in der Datenverwaltung, die in herkömmlichen Datenmanagement-Frameworks vorkommen, zu beheben.
Die Data-Fabric-Architektur verstehen
Der Begriff Data Fabric wird verwendet, um eine Datenmanagementarchitektur zu beschreiben, die darauf ausgelegt ist, einen nahtlosen und konsistenten Zugang zu und Verwaltung von Daten aus verschiedenen Quellen zu ermöglichen, einschließlich lokaler Systeme, cloudbasierter Systeme und anderer Arten von Datenspeichern.
Eine Data Fabric umfasst typischerweise eine Reihe von Tools und Technologien, die Datenintegration, Datenmanagement und Datenverwaltung im gesamten Daten-Ökosystem einer Organisation ermöglichen. Das Ziel einer Data Fabric ist es, Organisationen den Zugriff auf ihre Daten zu erleichtern und sie zu nutzen, um Erkenntnisse zu gewinnen, bessere Entscheidungen zu treffen und Geschäftsergebnisse zu verbessern.
Laut Gartner werden Data-Fabric-Einführungen die Effizienz der Datennutzung um 400 % verbessern und den Bedarf an menschlichem Eingreifen in das Datenmanagement um die Hälfte reduzieren.
Data Fabric vs. Data Mesh: Wesentliche Unterschiede
Was ist aber der Unterschied zwischen Data Fabric und Data Mesh? Während beide Architekturen entstanden sind, um die Herausforderungen zu mildern, denen sich Unternehmen in Bezug auf Datenmanagement gegenübersehen, erklärt James Serra, Data & AI Solution Architect bei Microsoft: „Data Fabric ist technologiezentriert, während ein Data Mesh sich auf organisatorischen Wandel konzentriert.“
Was eine Data Fabric letztendlich tut, ist höhere Effizienz durch den Einsatz von ML/AI zu ermöglichen und gleichzeitig Geschäftsteams zu befähigen, autonom als Datennutzer zu agieren und umsetzbare Erkenntnisse zu gewinnen.
Automotive Extra: Selbstfahrende Autos
Im Laufe unserer Existenz haben wir bei diconium uns einen Ruf als vertrauenswürdiger Partner für Mobilitäts- und Automobilkunden aufgebaut und umfangreiche Expertise in den Bereichen Cybersicherheit, Infotainment und autonomes Fahren entwickelt.
Fortschritte bei ADAS (Advanced Driver Assistance Systems) treiben die Innovation im Markt für selbstfahrende Autos voran, und zunehmend qualitative Datensätze ebnen den Weg für beschleunigte Entwicklungen.
Die Zukunft autonomer Fahrzeuge
Das Marktforschungsunternehmen Next Move Strategy Consulting schätzte den globalen Markt für autonome Fahrzeuge im Jahr 2022 auf 17.000 Einheiten, und es wird erwartet, dass der Markt bis 2030 auf etwa 127.000 Einheiten anwachsen wird. (Statista)
Welche anderen Datenmanagement-Trends erwartest du, dass sie in den kommenden Jahren an Schwung gewinnen werden? Kontaktiere unsere Kollegen, um zu besprechen, wie deine Organisation #applydatamesh nutzen kann, um den Wert deiner Daten zu steigern.