
In diesem Beitrag werden wir eine weitere Methode zur Effizienzsteigerung unseres ML-Modells untersuchen, die Wissensdestillation genannt wird. Stell dir folgende Situation vor: Du vermittelst einem Schüler einen komplexen Sachverhalt, indem du die wichtigsten Konzepte vereinfachst, sodass dieser das Wesentliche erfassen kann, ohne jedes Detail auswendig zu lernen. Genau das macht Wissensdestillation in der Welt des maschinellen Lernens: Die „Weisheit“ eines großen, leistungsstarken Modells wird auf ein kleineres, nutzerfreundlicheres Modell übertragen.
Was ist Wissensdestillation?
Wissensdestillation bezeichnet den Prozess des Wissenstransfers von einem größeren Modell auf ein kleineres Modell. Das größere, meist auch komplexere Modell wird als Lehrer bezeichnet, während das kleinere, effizientere Modell als Schüler bezeichnet wird. Wenn wir von größeren und kleineren Modellen sprechen, messen wir die Modellgröße anhand der Parameteranzahl.
Der Prozess der Wissensdestillation sieht so aus: Zunächst wird das Lehrermodell mit den Daten trainiert – alternativ kann auch ein bereits trainiertes Modell als Lehrermodell verwendet werden. Nach dem Training des Lehrermodells beginnt das Training des Schülermodells, das die Ausgaben des Lehrermodells vorhersagen soll.
Das Konzept der Wissensdestillation wurde erstmals von Jeffrey Hinton, Oriol Vinyals und Jeff Dean in ihrem 2015 vorgestellten Papier „Distilling the Knowledge in a Neural Network“ eingeführt.
Was ist das Ziel der Destillation?
Das Ziel ist, die Leistung des kleineren Modells so nahe wie möglich an das Lehrermodell zu bringen, während die für Inferenz und Deployment benötigten Rechenressourcen erheblich reduziert werden.
Wie funktioniert Wissensdestillation?
Das Training eines kleineren Schülermodells mit dem Wissen eines Lehrermodells umfasst mehrere wichtige Schritte.
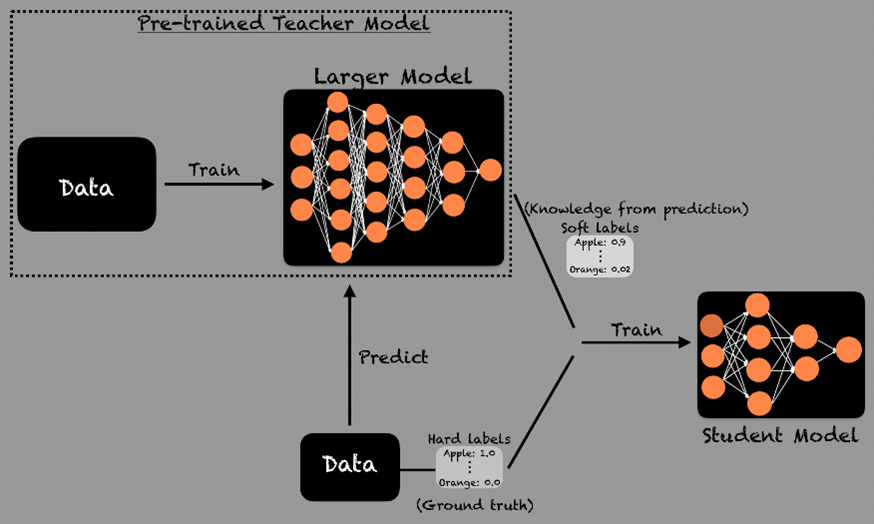
Zuerst erzeugt das Lehrermodell sogenannte „Soft Labels“. Dann beginnt man, das Schülermodell darauf zu trainieren, die Ausgaben des Lehrermodells vorherzusagen. Zusätzlich zum Training mit den Soft Labels lernt das Schülermodell auch anhand der tatsächlichen (ground truth) Labels. Beide Schritte helfen dem Schülermodell, die Schlussfolgerungsmuster des Lehrermodells zu erfassen, statt bloß korrekte Antworten auswendig zu lernen.
Sobald das Schülermodell vom Lehrermodell gelernt hat, kann es mit aufgabenspezifischen Datensätzen weiter angepasst werden (fine-tuning). Dies stellt sicher, dass das Schülermodell auch in realen Anwendungen gut abschneidet, selbst wenn es deutlich kleiner als das Lehrermodell ist.
Was sind Soft Labels?
Anstatt nur die richtigen Antworten zu geben, gibt das Lehrermodell Wahrscheinlichkeitsverteilungen über mögliche Antworten aus. Angenommen, du hast ein Klassifizierungsmodell, dann enthält das Set an Trainingsdaten pro Instanz nur ein Label. Das Lehrermodell hingegen gibt eine Wahrscheinlichkeitsverteilung über alle möglichen Labels, was viel mehr Informationen liefert. Anstatt nur „Apfel“ zu sagen, könnte das Lehrermodell z.B. „Apfel“ mit 90 % Wahrscheinlichkeit, „Pfirsich“ mit 5 %, „Birne“ mit 3 % und „Orange“ mit 2 % Wahrscheinlichkeit ausgeben.
Diese Soft Labels helfen dem Schülermodell, die Wahrscheinlichkeiten der Vorhersagen einzuschätzen, anstatt nur zwischen richtig und falsch zu unterscheiden. Da die Ausgaben des Lehrermodells mehr Informationen enthalten, lernt das Schülermodell daraus schneller und leichter.
Warum nutzt man Wissensdestillation bei LLMs?
Ein Hauptgrund ist die Effizienz. Kleinere LLMs benötigen weniger Rechenleistung und eignen sich somit für mobile oder Edge-Geräte oder andere Low-Latency-Anwendungen wie Echtzeitübersetzung oder Zusammenfassungen. Effizientere Modelle bedeuten Kosteneinsparungen, und geringerer Ressourcenverbrauch führt zu niedrigeren Inferenzkosten im Betrieb. Mit höherer Effizienz können mehr User und Aufgaben bewältigt werden, ohne in umfangreiche zusätzliche Infrastruktur zu investieren.
Ein weiterer Vorteil der Wissensdestillation bei LLMs ist, dass sich die Architektur des Schülermodells vom Lehrermodell unterscheiden kann. Hat das Lehrermodell beispielsweise 12 Transformer-Ebenen, muss das Schülermodell nicht ebenfalls 12 Ebenen haben – es könnten auch sechs oder zwei sein. Solche architektonischen Änderungen sind mit Quantisierung in der KI nicht wirklich möglich. Wissensdestillation hat im Vergleich zu anderen bekannten Methoden das größte Potenzial dazu, an Geschwindigkeit zu gewinnen.
Was sind die Herausforderungen von Wissensdestillation?
Erstens: Informationsverlust. Ein kleineres Modell kann womöglich nicht alle Feinheiten des großen Lehrermodells abbilden. Zweite Herausforderung ist die Gewährleistung, dass das destillierte Modell gut über verschiedene Aufgaben oder Domänen hinweg generalisiert.
Ein weiterer Nachteil ist der große Einrichtungsaufwand, da man das Trainingsdaten-Set organisieren muss (oft Milliarden von Tokens). Ist das Lehrermodell sehr groß, kann die Inferenz darauf während des Destillationsprozesses herausfordernd sein. Insgesamt ist Wissensdestillation also relativ kostenintensiv – praktisch nimmt es vielleicht 5–10 % der Rechenressourcen oder GPU-Stunden in Anspruch, die zum Training des Lehrermodells von Grund auf benötigt wurden.
Hier ein Beispiel: DistilBERT ist ein mit Wissensdestillation trainiertes Modell, bei dem BERT als Lehrermodell dient.

In diesem Modell wurde die Größe des BERT-basierten Modells um 40 % reduziert, wobei 97 % der Genauigkeit erhalten blieben. Die Autoren geben an, wie viele GPUs und wieviel Zeit das Training beanspruchte: DistilBERT wurde auf 8 GPUs etwa 90 Stunden lang trainiert, also insgesamt ca. 700 GPU-Stunden. Im Vergleich dazu benötigte das RoBERTa-Modell, das dem BERT-Modell ähnlich ist, einen Tag Training auf 1.000 GPUs, was etwa 24.000 GPU-Stunden (rund 20-mal mehr) entspricht. Das zeigt: Das Training mit Wissensdestillation geht deutlich schneller, benötigt aber immer noch erhebliche Rechenressourcen.
Welche Beispiele für destillierte Modelle gibt es in der Praxis?
Das bekannteste Modell ist DistilBERT, das aus BERT destilliert wurde (entwickelt von Google). DistilBERT ist 40 % kleiner, 60 % schneller und behält 97 % der BERT-Leistung bei. Ein weiteres Beispiel ist DistilGPT-2, das aus GPT-2 (entwickelt von OpenAI) destilliert wurde. DistilGPT-2 ist 35–40 % kleiner, 1,5-mal schneller und behält dabei 95–97 % der Leistung von GPT-2.
DeepSeek hat zudem kürzlich sechs aus DeepSeek-R1 destillierte Modelle vorgestellt, die auf Qwen und Llama basieren und beeindruckende Ergebnisse liefern. Laut deren Untersuchungen übertrifft das destillierte Qwen-14B-Modell das aktuelle Open-Source-Spitzenmodell QwQ-32B-Preview deutlich. Außerdem haben das destillierte Qwen-32B- und Llama-70B-Modell neue Bestleistungen in Schlussfolgerungstests unter den sogenannten „Dense Models“ erzielt.
Ausblick
Wissensdestillation wird bei LLMs immer beliebter werden, da sie die Berechnungskosten deutlich senkt, Inferenz beschleunigt und Echtzeit-KI auf Mobil-, Edge- und Cloud-Umgebungen ermöglicht – und das bei weitgehender Beibehaltung der Genauigkeit großer Modelle. Während sich die KI-Nutzung weiter skaliert, werden Unternehmen und Entwickler effiziente, bezahlbare und skalierbare Modelle priorisieren, um Anwendungen zu betreiben, die ohne eine immense Infrastruktur auskommen.
Author info
