
In der sich rasant entwickelnden Welt der Künstlichen Intelligenz werden Machine-Learning-Modelle immer größer und komplexer – von Sprachmodellen mit Milliarden von Parametern bis hin zu hochauflösenden Computer-Vision-Systemen. Doch diese Modelle erfordern enorme Rechenleistung, Speicher und Energie. Wie können wir sie verkleinern, ohne an Genauigkeit einzubüßen?
Hier kommt die Quantisierung ins Spiel – eine transformative Technik, die die Lücke zwischen hochmoderner KI und praktischer Anwendung schließt. Dabei werden hochpräzise Zahlen in Formate mit geringerer Präzision umgewandelt. Das Ergebnis? Deutlich kleinere Modelle, schnellere Inferenzzeiten und ein drastisch reduzierter Energieverbrauch.
In diesem Artikel klären wir, was Quantisierung eigentlich genau ist, wie sie funktioniert und warum sie so wichtig ist. Außerdem schauen wir uns verschiedene Ansätze wie Post-Training-Quantisierung und Quantization Aware Training (QAT) an – sowie bekannte Bibliotheken wie GGML, GGUF, GPTQ und mehr. Erstmal steigen wir mit den Gewichten in neuronalen Netzen ein.
Neuronale Netz-Gewichte
Gewichte sind die Parameter eines neuronalen Netzes, die bestimmen, wie das Netz lernt und Vorhersagen trifft. Dabei handelt es sich um reelle Zahlen, die mit jeder Verbindung zwischen den Neuronen im Netz verknüpft sind. Sie sind der Schlüssel dazu, dass das neuronale Netz Zusammenhänge zwischen Eingabedaten und den gewünschten Ausgabedaten erkennen kann.
Falls du dein Wissen über neuronale Netze erst einmal auffrischen möchtest, findest du eine Übersicht in unserem Blogpost zu den Unterschieden zwischen KI, Machine Learning und Deep Learning.
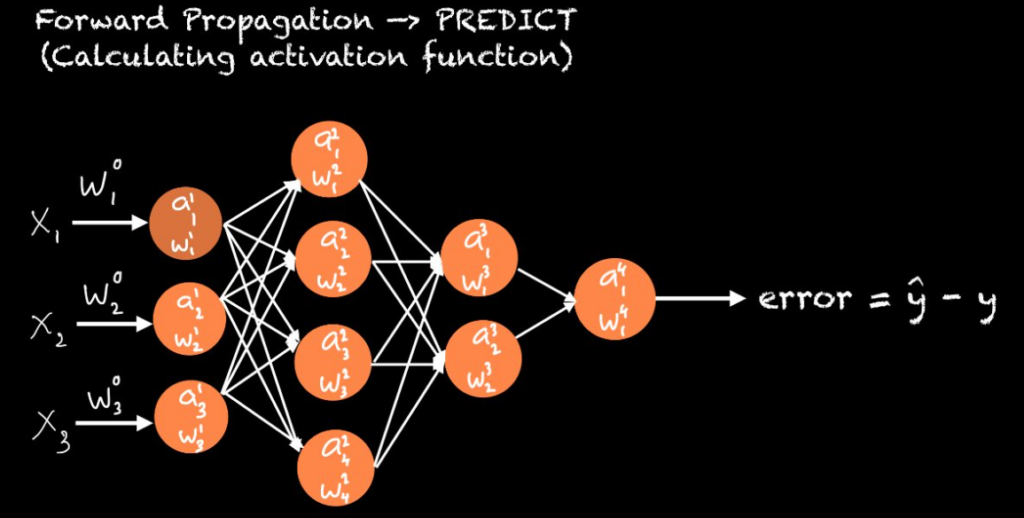
In einem neuronalen Netz erhält jedes Neuron Eingaben von anderen Neuronen. Jede dieser Eingaben wird mit einem Gewicht multipliziert, und die Summe aller gewichteten Eingaben wird anschließend durch eine Aktivierungsfunktion geleitet. Diese Aktivierungsfunktion entscheidet letztendlich, ob das Neuron aktiviert wird oder nicht.
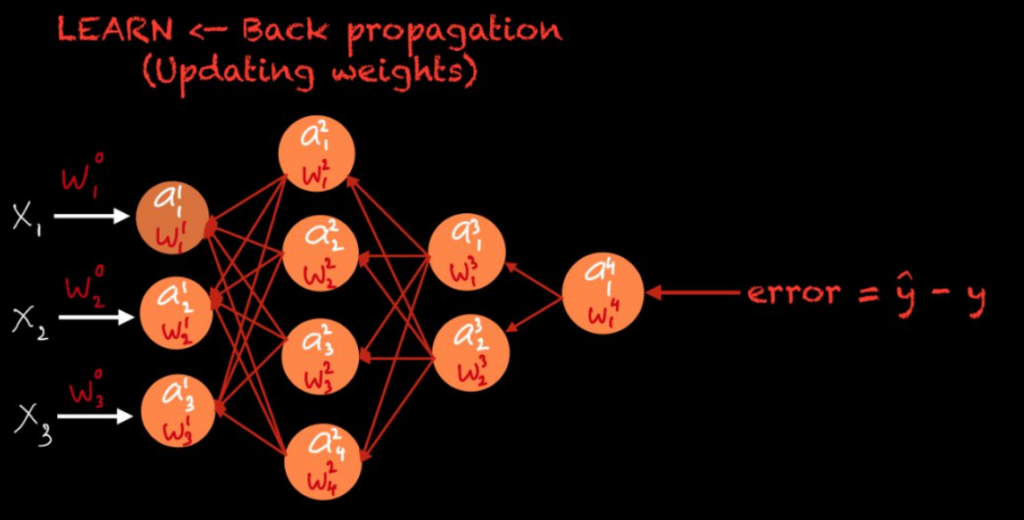
Anfangs werden die Gewichte zufällig initialisiert. Im Laufe des Trainingsprozesses werden sie jedoch optimiert und angepasst – je nach gewählter Optimierungsmethode. Dies bildet die Grundlage der Technik namens Backpropagation, im Deutschen auch Rückwärtspropagierung genannt. Backpropagation ermöglicht es, die Gewichte so anzupassen, dass der Fehler minimiert wird.
Wie hängen die Gewichte mit der Quantisierung zusammen?
Diese Gewichte werden im neuronalen Netz gespeichert – das sind die sogenannten Modellgewichte. Sie können mit unterschiedlicher Präzision gespeichert werden, z. B. als 32-Bit-Floating-Point, 16-Bit-Floating-Point, 8-Bit-Floating-Point, 8-Bit-Integer oder sogar 4-Bit-Integer.
Wenn wir von einem Gewicht sprechen, meinen wir eine Zahl, aber in einem Computer kann diese Zahl unterschiedliche Präzisionen und Datentypen haben. Je nach Präzision ändern sich viele Dinge, etwa die Rechenzeit für Inferenzen oder die Größe des neuronalen Netzes.
Ein Deep-Learning-Modell ist letztlich nichts anderes als ein neuronales Netz mit seinen Gewichten. Diese Gewichte, zusammen mit Biases und Aktivierungen, werden in Form von Matrizen gespeichert und multipliziert. Je höher die Präzision der gespeicherten Zahlen (z.B. 32-Bit-Floating-Point), desto größer ist das Modell und desto mehr Rechenleistung wird für die Inferenz benötigt.
Wenn die Gewichte mit hoher Präzision gespeichert werden, kann das Modell sehr groß werden. Mehr Präzision bedeutet genauere Zahlenwerte, aber reduziert man die Präzision, verringert sich auch die Modellgröße. Hier kommt ein spannendes Verfahren ins Spiel: die Quantisierung.
Was ist Quantisierung?
Quantisierung in neuronalen Netzen bedeutet, die Präzision von Gewichten, Biases und Aktivierungen zu reduzieren, um die Modellgröße und die Rechenanforderungen zu senken – ohne die Genauigkeit des Modells signifikant zu beeinträchtigen.
Es gibt zwei Hauptarten der Quantisierung:
- Post-Training-Quantisierung (PTQ)
- Quantization Aware Training (QAT)
Bei GGML, GGUF und GPTQ-Modellen wird in der Regel Post-Training-Quantisierung angewendet.
Was ist Post-Training-Quantisierung?
Post-Training-Quantisierung bedeutet, ein bereits trainiertes neuronales Netz nachträglich zu quantisieren. (Ich habe bereits einen Artikel über das Thema Pre-training und Fine-tuning von LLMs geschrieben, falls du mehr darüber erfahren möchtest.) Dabei werden Gewichte und Aktivierungen auf eine niedrigere Präzision gerundet, was allerdings zu einem gewissen Genauigkeitsverlust führen kann. Zum Beispiel könnte ein Modell mit 16-Bit-Floating-Point-Präzision auf 8-Bit- oder 4-Bit-Integer reduziert werden.
Durch diese Quantisierung verringern sich die Modellgröße und die Hardware-Anforderungen, sodass das Modell auch auf weniger leistungsstarken Geräten schneller ausgeführt werden kann. Allerdings kann es dadurch zu leichten Einbußen bei der Vorhersagegenauigkeit kommen.
Die bekanntesten quantisierten Modelltypen sind GGML und GPTQ. Auch GGUF, AWQ und EXL2 sind quantisierte Modellformate, die zur Reduktion der Rechenanforderungen genutzt werden.
GGML
GGML ist eine leistungsstarke Tensor-Bibliothek und eines der ersten Datei-Formate für OpenAI’s GPT-Modelle. GGML war das Dateiformat, das direkt vor GGUF existierte und von Georgi Gerganov entwickelt wurde. Der Name ist eine Kombination aus den Initialen Gerganovs, GG, und ML für Machine Learning. Ziel war es, LLMs auf standardmäßiger Hardware zugänglich zu machen.
GGML unterstützt verschiedene Quantisierungsformate, darunter 16-Bit-Float sowie Integer-Quantisierung (4-Bit, 5-Bit, 8-Bit, etc.). Es ist für Apple M1/M2-Prozessoren und x86-Architekturen optimiert, schnell, portabel und in C/C++ geschrieben. Außerdem erlaubt es die einfache Konvertierung von Modellen aus anderen Frameworks (z. B. TensorFlow, PyTorch).
GGUF
GGUF ist ein verbessertes Datei-Format für Modelle, die mit GGML und ähnlichen Frameworks genutzt werden. Es wurde als Nachfolger von GGML entwickelt und optimiert die Speicherung und Verarbeitung von Modellen. Die Modelle wurden mit PyTorch oder einem anderen Framework erstellt und dann in GGUF für die Verwendung in GGML konvertiert.
Während GGML ein erster Versuch war, Modelle auf Standardhardware effizienter auszuführen, adressiert GGUF dessen Einschränkungen und stellt einen Fortschritt in den Dateiformaten für Sprachmodelle dar. GGUF zielt darauf ab, die Schwächen von GGML zu überwinden und die Benutzererfahrung zu verbessern, indem es mehr Daten über das Modell bereitstellt und mehrere Architekturen unterstützt. Sowohl GGUF als auch GGML nutzen die CPU zum Ausführen von LLMs, übertragen jedoch auch einige seiner Schichten auf die GPU, um den Prozess mithilfe deiner GPU zu beschleunigen.
GPTQ
Generative Post-Trained Quantization (GPTQ) ist eine Quantisierungsbibliothek, die speziell für GPU-optimierte Quantisierung entwickelt wurde. Sie kann die Modellgröße um das Vierfache reduzieren und eignet sich besonders für Systeme mit leistungsfähigen GPUs. Das Prinzip hinter GPTQ ist, alle Gewichte auf eine 4-Bit-Quantisierung zu komprimieren und dabei den Mean Squared Error (MSE) der Gewichte zu minimieren. Während der Inferenz werden die Gewichte dann dynamisch auf Float16 hochgerechnet, um eine hohe Performance bei geringem Speicherverbrauch zu ermöglichen.
Falls dein GPU zu schwach für GPTQ ist, lohnt es sich, auf CPU-optimierte Methoden wie GGUF umsteigen.
AWQ
Activation-aware Weight Quantization (AWQ) ist eine alternative Quantisierungsmethode zu GPTQ. Der Hauptunterschied besteht darin, dass AWQ nicht alle Gewichte gleich behandelt – einige besonders wichtige Gewichte werden bei der Quantisierung ausgelassen, um Genauigkeitsverluste zu minimieren. Laut Forschungsergebnissen kann AWQ eine erhebliche Geschwindigkeitssteigerung im Vergleich zu GPTQ bieten, während die Modellleistung vergleichbar bleibt oder sich sogar verbessert.
EXL2
ExLlamaV2 (EXL2) ist eine Inference-Bibliothek für die lokale Ausführung von LLMs auf modernen Verbraucher-GPUs. Es ist eine weiter optimierte Form der Quantisierung, die geringe Latenzzeiten ermöglicht. EXL2 zielt auf noch höhere Effizienz und geringere Speicheranforderungen ab, was besonders nützlich für Echtzeitanwendungen ist.
Was ist Quantization Aware Training (QAT)?
Wir können das Quantization Aware Training entweder mit einem vortrainierten Modell oder einem Post-Training Quantized (PTQ) Modell beginnen. Dann verfeinern wir dieses Modell mit QAT. Das Ziel hierbei ist es, den Genauigkeitsverlust, der aufgrund von PTQ aufgetreten ist, wiederherzustellen, wenn wir ein PTQ-Modell verwendet haben.
Der Vorwärtsschritt (forward pass) wird durch QAT beeinflusst, während der Rückwärtsschritt (backward pass) unbeeinflusst bleibt. Beim Quantization Aware Training wird die Quantisierung für Schichten durchgeführt, die keinen übermäßigen Verlust in der Genauigkeit verursachen, wenn ihre Parameter quantisiert werden. Umgekehrt bleiben Schichten, deren Quantisierung die Genauigkeit reduziert, unquantisiert.
Das grundlegende Konzept von QAT besteht darin, die Eingabe in eine niedrigere Präzision basierend auf der Gewichtspräzision dieser Schicht zu quantisieren. QAT stellt auch sicher, dass das Ergebnis der Multiplikation von Gewichten und Eingaben in höhere Präzision zurückkonvertiert wird, wenn die nächste Schicht dies erfordert. Dieser Vorgang, die Eingabe auf niedrigere Präzision zu konvertieren und dann das Ergebnis der Gewichts- und Eingabemultiplikation wieder auf höhere Präzision zu konvertieren, wird auch als „FakeQuant Node Insertion“ bezeichnet („Fake“ wird hier verwendet, weil es erst quantisiert und dann wieder dequantisiert wird).
Der Lernprozess des Modells
QAT führt einen Quantisierungsfehler im Vorwärtsschritt ein, der sich zum Fehler akkumuliert und dann im Rückwärtsschritt mit einem Optimierer abgestimmt wird. Durch die Simulation des Quantisierungsfehlers während des Trainings kann das Modell lernen, sich selbst zu optimieren, indem es den durch die Quantisierung eingeführten Fehler reduziert.
Gewichte sind die Parameter in einem neuronalen Netz, die bestimmen, wie das Modell lernt und Vorhersagen trifft. Jedes Gewicht ist eine reelle Zahl, die einer Verbindung zwischen zwei Neuronen im Netz zugeordnet ist. Durch das Anpassen dieser Gewichte während des Trainings lernt das neuronale Netz, Zusammenhänge zwischen den Eingangsdaten und den gewünschten Ausgaben zu erkennen.
Quantisierung bezeichnet den Prozess, bei dem die Genauigkeit der Gewichte, Biases und Aktivierungen eines neuronalen Netzes reduziert wird. Ziel ist es, die Modellgröße und den Rechenaufwand zu verringern. In vielen Fällen lässt sich dies erreichen, ohne die Genauigkeit des Modells stark zu beeinträchtigen. Es gibt zwei Ansätze für die Quantisierung: Post-Training-Quantisierung (nachträgliche Quantisierung) und Quantization-Aware Training (QAT), also quantisierungsbewusstes Training.
Beim Quantization-Aware Training wird ein bereits trainiertes oder nachträglich quantisiertes Modell weiter fein abgestimmt, um Genauigkeitsverluste durch die Quantisierung auszugleichen. Während des QATs werden Eingaben und Gewichte im Vorwärtsschritt (Forward Pass) vorübergehend quantisiert, während der Rückwärtsschritt (Backward Pass) in voller Genauigkeit bleibt. Schichten, bei denen durch Quantisierung zu große Genauigkeitsverluste entstehen würden, bleiben unquantisiert. Dieses Verfahren – oft „FakeQuant Node Insertion“ genannt – simuliert Berechnungen mit geringerer Genauigkeit, erhält dabei aber weitgehend die Gesamtpräzision des Modells.
Author info
