
Der Erfolg von LLMs stützt sich vor allem auf zwei Konzepte: Transformer und unsupervised pre-training. Die Kombination dieser Innovationen ermöglichte erstaunliche Ergebnisse bei downstream Tasks.
Wie wird GPT trainiert?
Wenn wir uns ansehen, wie GPT trainiert wird, bassiert es auf zwei Trainingstechniken: Unsupervised Pre-training mit dem Transformer auf sehr großen Datenmengen und Supervised Fine-tuning. Es erforderte außerdem spezifische Anpassungen an der Architektur. Selbst ohne aufgabenspezifische Modifikationen begannen wir, erstaunliche Ergebnisse zu beobachten.
Im Folgenden sollen diese beiden Kernelemente genauer vorgestellt werden.
Was ist Unsupervised Pre-training im LLM?
Wir könnten den Überblick verlieren, wenn wir in der Betrachtung von LLMs zu starr in binären Kategorien wie supervised oder unsupervised Learning denken. Unsupervised pre-Training basiert auf der Technik des semi-supervised Sequence Learning, das unsupervised und supervised Learning kombiniert. Obwohl wir es als unsupervised bezeichnen, nutzt es tatsächlich einen semi-supervised Ansatz.
Pre-Training bei LLMs beschreibt das Training eines transformerbasierten Modells auf sehr großen Textmengen, die überwiegend nicht gelabelt sind. Als Lernziel dient dabei in der Regel die Vorhersage des nächsten Tokens. Auch wenn dieser Schritt häufig als „unüberwacht“ bezeichnet wird, lässt er sich treffender als semi-überwachtes Sequenzlernen beschreiben: Das Modell erlernt allgemeine Sprachrepräsentationen, die anschließend durch Fine-Tuning gezielt auf spezifische Downstream-Aufgaben angepasst werden können.
Fine-Tuning bezeichnet den Prozess, bei dem die Gewichte bzw. Parameter eines vortrainierten LLMs mit einem aufgabenspezifischen, überwachten Datensatz gezielt weiter angepasst werden. Zwar können vortrainierte Modelle viele Aufgaben bereits allein durch geschicktes Prompting bewältigen, Fine-Tuning wird jedoch eingesetzt, um Leistung, Zuverlässigkeit und das Alignment des Modells für konkrete Anwendungsfälle wie Textgenerierung, Klassifikation, Zusammenfassungen oder das Befolgen von Instruktionen deutlich zu verbessern.
Data Labeling
Das verbessert die Leistung der Dokumentklassifizierung unter Verwendung eines unsupervised pre-training-Ansatzes eines LSTM (long short-term memory)-Netzwerks, gefolgt von supervised Fine-tuning. Anfangs wurden ungelabelte Daten verwendet, und die unsupervised Vorhersage dessen, was als Nächstes kommt, ermöglichte es uns, die Daten zu labeln. Nach diesem Pre-Training-Schritt wurde das rekurrente neuronale Netzwerk (das LSTM) stabiler und generalisierte besser als jeder andere zuvor verwendete Ansatz.
Übrigens, wenn du mehr über Data Labeling erfahren möchtest, vor allem mit Fokus auf der Automobilbranche, lies gerne den Artikel meiner Kollegin Dana: Data Labeling als kontinuierlicher Service.
Einführung des ULMFiT Papers
Eine weitere Schlüsselidee stammte aus einem Paper mit dem Titel „Universal Large Model fine tuning for text classification paper“ („ULMFiT paper“). Das war im Wesentlichen der Zeitpunkt, bei dem viel Aufmerksamkeit auf Computer Vision und Transfer Learning lag. Die Kernaussage ist, dass ein vortrainiertes Modell feinabgestimmt werden kann, um bei vielen verschiedenen Klassifizierungsaufgaben den neuesten Stand der Technik zu erreichen. Das bedeutet, dass wir einige der Transfer-Learning-Methoden auch bei der Verarbeitung natürlicher Sprache einsetzen können. Wir können also ein Vortraining durchführen und dann eine Feinabstimmung vornehmen, um bei der Klassifizierung wirklich gute Ergebnisse zu erzielen.
Wir können also die Idee des „semi supervised Sequence Learning“ nutzen, um ein „unsupervised pre-training“ durchzuführen, und dann kann dieses vortrainierte Modell für viele verschiedenen Klassifizierungsaufgaben feinabgestimmt werden.
Was ist Supervised Fine-tuning im LLM?
Nachdem das Modell mit einer großen Datenbasis trainiert wurde, sagt es das nächste Wort regressiv voraus. Bei manchen Aufgben ist es sinnvoll, mit einem vortrainierten Modell zu arbeiten, bei anderen nicht. Unabhängig davon kannst du ein vortrainiertes Modell für bestimmte Aufgaben feinabstimmen.
Supervised Fine-tuning ist typischerweise aufgabenspezifisch und kann für generative oder nicht-generative Aufgaben genutzt werden. Im Kontext von LLMs sprechen wir über generatives supervised Fine-tuning, aber wir können auch für nicht-generative Aufgaben wie Klassifikation, Ähnlichkeiten oder logische Schlussfolgerungen fine-tunen. Pre-trained LLM-Modelle wie GPT-2 und GPT-3 zeigen bessere Ergebnisse in generativen Aufgaben und anderen Sprachaufgaben wie dem Beantworten von Fragen, Zusammenfassungen und Übersetzungen. Sie erzielen bessere Ergebnisse ohne Fine-tuning, einfach durch Prompting.
Die drei verschiedenen Learning-Methoden
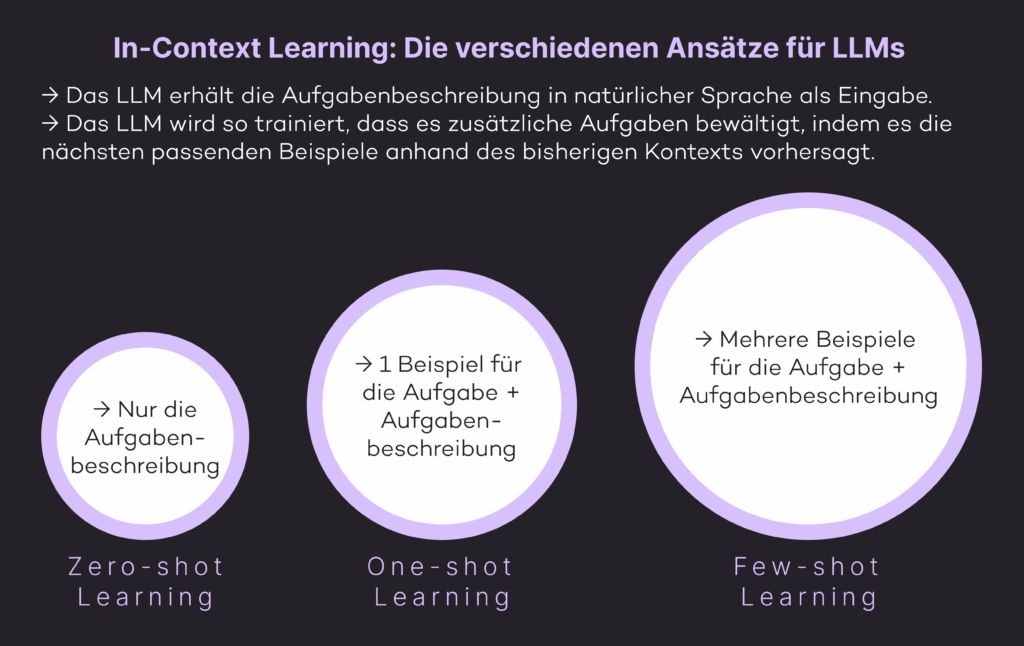
Zero-shot Learning: Keine aufgabenspezifischen Daten sind erforderlich; das Modell kann die Antwort nur mit einer natürlichen Sprachbeschreibung der Aufgabe vorhersagen.
One-shot Learning: Ein einziges Lösungsbeispiel wird zusätzlich zur Aufgabenbeschreibung bereitgestellt.
Few-shot Learning: Mehrere Lösungsbeispiele werden mit der Aufgabenbeschreibung bereitgestellt.
All diese zero, one und few-shot Learning Methoden sind kein Fine-tuning, da keine Gradientenaktualisierungen durchgeführt werden. Es sind In-Context Learning-Ansätze, bei denen der Input für die Aufgabenstellung in natürlicher Sprache mit einigen Beispielen erfolgt, und vom LLM wird erwartet, dass es weitere Lösungen erschließt, indem es die nächsten Vorkommnisse vorhersagt.
Beim Supervised Fine-tuning aktualisiert das Modell die Gewichtungen des vortrainierten Modells durch Training an einem supervised Datensatz, der typischerweise zwischen 1 und 100.000 aufgabenspezifische Beispiele umfasst.
Instruction Tuning
Instruction tuning ist auch ein supervised Fine-tuning-Ansatz, erfordert jedoch keinen viel größeren Datensatz. Statt Input- und Output-Datenbeispiele bereitzustellen, benötigt es Prompt- und Completion-Paare, die das erwartete Verhalten demonstrieren. Instruction tuning ermöglicht es Modellen, schnell und mit weniger Beispielen angepasst zu werden, was effizienter ist als die umfangreichen Datensätze, die für das Fine-tuning benötigt werden, oder die iterativen Feedback-Schleifen von RLHF. Es verlässt sich stark auf Prompt- und Completion-Beispiele, was jedoch zu Inkonsistenzen und Unvorhersehbarkeit führen kann, wenn der Prompt nicht sorgfältig erstellt wird. Instruction Fine-tuning trainiert das Modell anhand von Beispielen, die zeigen, wie es auf bestimmte Anweisungen reagieren soll.
Zero-Shot-, One-Shot- und Few-Shot-Learning sind Methoden des In-Context-Learnings. Dabei passt sich das Modell über natürliche Sprachinstruktionen und Beispiele im Prompt an eine Aufgabe an, ohne dass die Gewichte verändert werden. Beim Fine-Tuning hingegen werden die Modellparameter anhand eines überwachten Datensatzes durch Gradienten-Updates angepasst, was zu dauerhaften Veränderungen im Verhalten des Modells führt.
Was sind RLHF, RLAIF und DPO?
Diese drei Techniken werden allgemein zur weiteren Ausrichtung von LLMs verwendet. Das bedeutet, das Verhalten von LLMs an menschliche Präferenzen anzupassen. LLM-Ausrichtungen können ebenfalls als Fine-tuning-Ansatz betrachtet werden, ist aber kein Supervised Fine-tuning.
RLHF
RLHF steht für „Reinforcement Learning from Human Feedback“, das für Aufgaben verwendet wird, bei denen es schwierig ist, eine klare, algorithmische Lösung zu definieren. Es hat zwei Hauptkomponenten: Reinforcement Learning (RL) und Human Feedback (HF).
Menschen können den Output des Modells in diesem Ansatz leicht bewerten. Wenn eine höfliche Antwort vom Modell erwartet wird, während Verzerrungen vermieden werden sollen, aber klare Regeln nicht verfügbar sind, ist RLHF der beste Ansatz, um dieses Problem zu lösen. Wenn wir über LLM-Training sprechen, meinen wir nur die Aktualisierung der Parameter des Sprachmodells. Wenn wir jedoch RLHF verwenden, trainieren wir die Parameter von drei separaten Modellen:
- LLM: pre-trained LLM, das auf der Grundlage von Instruktionsdaten feinabgestimmt wird.
- Reward Model: Training auf der Grundlage menschlicher Feedback-Daten, um menschliche Präferenzen vorherzusagen und Belohnungssignale zur Stärkung des Strategiemodells zu liefern.
- Policy Model: verwendet Reinforcement Learning mit dem „Reward Model“ als Feedback-Quelle und wird so trainiert, dass es Tokens erzeugt, indem es die vorhergesagte Belohnung maximiert.
Die Gewichtungen des LLMs werden in der Phase des Reinforcement Learning angepasst und fein abgestimmt. Hier lernt das Modell, seine Aktionen zu optimieren, um die Belohnungen zu maximieren. RLHF verbessert LLMs, um effizienter und zuverlässiger zu sein, indem es das Feedback von menschlicher Bewertung einbezieht.
RLAIF
„Reinforcement Learning from AI Feedback“ ist eine vergleichsweise neue Technik, die es ermöglicht, Verstärkungslernmodelle zu trainieren, ohne auf menschliche Trainingsdaten angewiesen zu sein. Das Sammeln menschlichem Feedbacks ist teuer und zeitaufwendig. RLAIF bietet einen Weg, dieses Nadelöhr zu umgehen, indem menschliche Bewerter:innen durch einen LLM-Labeler ersetzt werden. RLAIF verwendet Präferenzen, die von einem großen Sprachmodell (LLM) generiert werden, um das Verstärkungslernmodell zu trainieren. Laut Forschern kann RLAIF die Leistung von herkömmlichem RLHF bei Textzusammenfassungsaufgaben erreichen.
DPO
DPO steht für Direct Preference Optimization. Ziel ist es hier, LLMs anhand eines einfacheren, speichereffizienteren Algorithmus auszurichten als herkömmliche Alignment-Techniken, die von OpenAI und Anthropic entwickelt wurden. Die Grundidee besteht darin, das Optimierungsziel so zu ändern, dass es direkt die Präferenzen codiert oder implizit modelliert, die ein Reward Model lernen würde. Anstatt also drei Modelle zu benötigen (SFT-Modell, Hauptmodell und Reward Model), optimiert DPO die Parameter des ursprünglichen Sprachmodells direkter.
Was sind PEFT und LoRA im Fine-tuning der LLM?
Das Problem beim Training großer Sprachmodelle und deren Fine-tuning besteht darin, dass wir letztendlich sehr große Datenmengen erhalten. Dies führt zu mehreren Problemen:
1. Man braucht viel mehr Rechenleistung zum Trainieren. Da die Modelle immer größer werden, benötigen Sie mehr und viel größere GPUs zur Feinabstimmung.
2. Die Dateigrößen werden riesig. Die großen Sprachmodelle mit Milliarden von Parametern nehmen ständig an Größe zu.
Hier kommt Parameter Efficient Fine-tuning (PEFT) ins Spiel. PEFT verwendet verschiedene Techniken. LoRA, das für Low-Rank Adaptation steht, stammt aus einer wissenschaftlichen Arbeit, die sich darauf konzentriert, dies für LLMs zu tun. Andere Techniken unter PEFT umfassen Prefix Tuning, P-tuning und Prompt Tuning, auf die in diesem Beitrag nicht eingegangen wird.
Katastrophales Vergessen
PEFT, insbesondere mit LoRA, ermöglicht es, nur eine kleine Anzahl zusätzlicher Gewichtungen im Modell zu fine-tunen, während die meisten Parameter des vortrainierten Netzwerks unangetastet bleiben. Die Idee hier ist, dass wir die ursprünglichen Gewichtungen tatsächlich nicht trainieren. Stattdessen fügen wir einige zusätzliche Gewichtungen hinzu und fine-tunen diese.
Ein Vorteil davon ist, dass die ursprünglichen Gewichtungen erhalten bleiben, was dazu beiträgt, das „katastrophale Vergessen“ zu verhindern. Katastrophales Vergessen tritt auf, wenn Modelle während des Fine-Tunings vergessen, wie sie ursprünglich trainiert wurden. Bei zu viel Fine-Tuning kann es sein, dass das Modell ursprüngliche Trainingsdaten vergisst.
Die Vorteile des PEFT (Parameter Efficient Fine-tuning)
PEFT hat dieses Problem nicht, da es zusätzliche Gewichtungen hinzufügt und diese abstimmt, während die ursprünglichen Gewichtungen bestehen bleiben. PEFT ermöglicht außerdem ein effektives Fine-tuning mit einer kleinen Menge an Daten und generalisiert besser auf andere Szenarien.
Insgesamt ist es ein großer Gewinn für das Fine-tuning großer Sprachmodelle und sogar Modelle wie Stable Diffusion, die beginnen, diese Technik ebenfalls zu verwenden. Einer der besten Aspekte ist, dass es nur zu kleinen Checkpoints führt. Es verbraucht weniger Ressourcen und erhält die ursprünglichen Gewichtungen. Im Allgemeinen ermöglichen es PEFT-Ansätze nur durch Hinzufügen zusätzlicher Gewichtungen, eine ähnliche Leistung zu erzielen wie beim Fine-tuning eines vollständigen Modells.
Reinforcement Learning from Human Feedback (RLHF) ist eine Methode, um Sprachmodelle besser auf menschliche Erwartungen auszurichten. Nach dem Fine-Tuning wird das Modell zusätzlich mit Rückmeldungen von Menschen trainiert: Zuerst wird eine Art „Belohnungsmodell“ erstellt, das bewertet, wie gut eine Antwort ist. Dieses Belohnungsmodell hilft dann, das Sprachmodell über Verstärkungslernen so anzupassen, dass seine Antworten hilfreicher, korrekter und verständlicher werden – besonders in Situationen, in denen feste Regeln schwer festzulegen sind.
Parameter Efficient Fine-Tuning (PEFT) umfasst Methoden, mit denen große Sprachmodelle gezielt angepasst werden können, ohne alle Modellgewichte zu verändern. Stattdessen werden nur wenige zusätzliche Parameter trainiert, während die ursprünglichen Gewichte unverändert bleiben. So lassen sich Modelle effizient fine-tunen, ohne viel Rechenleistung oder Speicher zu benötigen.
LoRA (Low-Rank Adaptation) ist eine weit verbreitete Methode des Parameter Efficient Fine-Tuning (PEFT). Sie ermöglicht es, ein Modell effizient anzupassen, indem nur wenige zusätzliche Parameter trainiert werden. Dadurch werden Rechenaufwand und Speicherbedarf deutlich reduziert, katastrophales Vergessen vermieden und sehr kleine Checkpoints erzeugt, während die Leistung des Modells fast genauso hoch bleibt wie bei einem vollständigen Fine-Tuning.
Author info
