
Einleitung
In einem früheren Blogbeitrag haben wir das Konzept der kontinuierlichen KI-Absicherung durch die Metapher einer futuristischen KI-Produktionsfabrik, die in sicherheitskritischen Bereichen operiert, erforscht. Wir stellten uns KI-Systeme als Glaskuben vor, die auf Förderbändern innerhalb dieser Fabrik bewegt wurden. Die gesamte Montage – Förderbänder, Inspektionsinstrumente und alles andere – symbolisierte unser kontinuierliches System zur KI-Absicherung. Das primäre Ziel dieses Rahmenwerks besteht darin, die KI-Systeme entlang der gesamten Kette ihrer Entwicklung gründlich zu untersuchen und ihre Komponenten bis ins kleinste Detail zu zerlegen, um sowohl ihre individuellen als auch ihre kollektiven Funktionen zu bewerten.
Der Start des Forschungsprozesses
In diesem Blogbeitrag machen wir einen ersten Schritt vorwärts auf dem weg, diese Vision zu konkretisieren. Die Idee der kontinuierlichen KI-Absicherung hat sich organisch ergeben im Rahmen meiner Forschung zur Frage, wie die Testung und Validierung der richtigen Funktionalität von KI-Softwarekomponenten am besten zu gewährleisten wäre. Dieser Forschungsprozess begann mit einer Publikation von R. Kaur und Kollegen, betitelt „Assurance Case Patterns for Cyber-Physical Systems with Deep Neural Networks“. Der Gegenstand der Publikation ist die Herausforderung, die Sicherheit von sogenannten Kybernetisch-Physikalischen Systemen (KPS) zu überprüfen. Diese KPS können eins oder mehr KI-Elemente, wie zum Beispiel Tiefe Neuronale Netze (TNN) enthalten.
Was ist ein Kybernetisch-Physikalisches System?
Um besser zu veranschaulichen, was ein KPS sein kann, stelle man sich zum Beispiel ein Auto vor, das mit integrierten Softwarekomponenten und mehreren Fahrassistenzsystemen ausgestattet ist. Ebenso könnte ein KPS ein medizinisches Gerät, ein industrielles Robotik System oder eine Vielzahl ähnlicher Einheiten sein, die potenziell in sicherheitskritischen Domänen eingesetzt werden.
Die Grundlage der Untersuchung
Während sich die Publikation von Kaur und Kollegen hauptsächlich auf die nachweisbare Verifikation der Sicherheit von KPS mit TNN konzentrierte, veranlasste es mich, eine umfassendere Sichtweise auf die Verifikations- und Validierungsprozesse moderner Systeme mit KI-Elementen zu übernehmen. Diese Perspektive integriert die Sicherheitsverifikation als einen zentralen, aber nicht alleinigen Aspekt der KI-Absicherung. Folglich habe ich – in enger Zusammenarbeit mit Kolleginnen und Kollegen aus unterschiedlichen Forschungs- und Entwicklungsbereichen – eine umfassende Untersuchung verschiedener KI-Testungswerkzeuge unternommen. Diese Werkzeuge haben wir in vier verschiedene Wekzeugtypen klassifiziert:
- Diagnose: Werkzeuge, die das Entscheidungsverhalten eines KI-Elementes analysieren.
- Unsicherheitsabschätzung: Werkzeuge, welche die Unsicherheit quantifizieren und bewerten, die den Entscheidungen des KI-Elementes innewohnt.
- Robustheitsbewertung: Werkzeuge, welche die Robustheit der KI-Entscheidungen unter verschiedenen Eingabestörungen evaluieren und messen.
- Sicherheitsverifikation: Werkzeuge, welche die Sicherheit von KI-Elementen hinsichtlich vordefinierter Eigenschaften nachweislich verifizieren. Dies können beispielsweise mathematische Eigenschaften sein, die bestimmte Eingaben mit erwarteten Ausgaben korrelieren.
In diesem Beitrag stelle ich nun als erstes wichtiges Element eines Systems zur Kontinuierlichen KI-Absicherung die Klasse der Diagnosewerkzeuge anhand von Beispielwerkzeugen in der Klasse vor. In den zukünftig zu veröffentlichenden Blogbeiträgen werde ich dies auf ähnliche Weise für die anderen drei Säulen des KI-Absicherungs-Rahmenwerks durchführen.
Diagnosewerkzeuge
Das Ziel von Diagnosewerkzeugen besteht darin, die Entscheidungsprozesse von KI-Modellen transparent zu machen. Diese Transparenz ist besonders wichtig für TNN-Modelle, die oft als sog. „Black-Box“-Modelle bezeichnet werden, da ihre inneren Abläufe komplex und undurchsichtig sind. Das angemessene Verfolgen und Verstehen der Entscheidungsprozesse dieser Modelle ist grundlegend für deren zuverlässigen und vertrauenswürdigen Einsatz. Innerhalb der Diagnosewerkzeuge unterteilen wir die Werkzeuge in zwei Unterkategorien:
- Werkzeuge zur Entscheidungserklärung: Diese Werkzeuge zielen darauf ab, die Muster zu extrahieren und zu visualisieren, welche die Entscheidungen des Modells bestimmen.
- Werkzeuge zur Modelldiagnose: Diese Werkzeuge untersuchen die Mechanismen, die während des Entscheidungsprozesses innerhalb des Modells ablaufen. Sie können die Effektivität des Trainingsprozesses expliziter Modellschichten in einem TNN bewerten und feststellen, ob Schichten untertrainiert sind, übertrainiert sind, und so weiter.
Lassen Sie uns nun einige Beispielwerkzeuge innerhalb dieser Unterkategorien etwas tiefer untersuchen.
Werkzeuge zur Entscheidungserklärung
Unsere Arbeit mit KI-Absicherung und die Gewährleistung vertrauenswürdiger KI hat sich in den letzten Jahren hauptsächlich auf die KI-System in der Domäne des Maschinellen Sehens („Computer Vision“) konzentriert. Folglich hat sich unsere Forschung zu den Werkzeugen zur Entscheidungserklärung auch auf solche fokussiert, die für Anwendungen im Bereich des Maschinellen Sehens optimiert sind, obwohl einige dieser Werkzeuge breiter auf verschiedene KI-Kontexte anwendbar sind.
Layer-wise Relevance Propagation (LRP) – Ein auf Maschinelles Sehen fokussiertes Wekzeug
Layer-wise Relevance Propagation (LRP) ist eine solche Methode, die speziell für KI-Systeme im Bereich des Maschinellen Sehens am Fraunhofer Heinrich-Hertz-Institut entwickelt wurde (siehe im paper für Details zur Methode). LRP visualisiert den Beitrag einzelner Pixel zu den Vorhersagen des Modells durch sog. „Heat Maps“. In einem technischen Paper, charakterisieren die Autoren LRP wie folgt:
“… Wir führen eine Methodik ein, die es erlaubt, die Beiträge einzelner Pixel zu Vorhersagen zu visualisieren … Diese Pixelbeiträge können als Heat Maps visualisiert werden und einem menschlichen Experten bereitgestellt werden, der intuitiv nicht nur die Gültigkeit der Klassifikationsentscheidung überprüfen, sondern auch eine weitere Analyse auf interessante Regionen konzentrieren kann.”
Ohne in die technischen Feinheiten von LRP einzutauchen, veranschaulichen wir seine Anwendung mit einem Beispiel (für weitere Beispiele siehe die Haupt-Repository und due Pytorch-Repository).
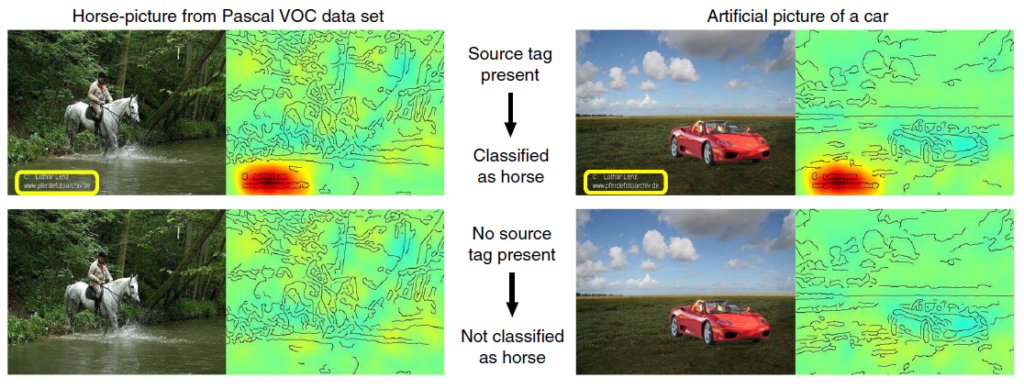
Wie man sieht, stützt sich die Klassifikation des Modells inkorrekt auf ein Künstler-Tag, das in den Trainingsdatenbildern mit Pferden konsistent vorkommt. Wenn das Tag entfernt wird, erkennt der Klassifikator das Pferd nicht, was ein typisches Beispiel für Ungewolltes Shortcut-Lernen darstellt. Dieses Problem verdeutlicht die Tendenz des Modells, einfache, nicht verallgemeinerbare Muster in den Daten auszunutzen und somit seine Zuverlässigkeit zu beeinträchtigen. Solche Herausforderungen beschränken sich nicht auf triviale Fälle. Ein KI-Algorithmus, der z.B. Lungenkrankheiten in Röntgenbildern erkennt, könnte fälschlicherweise auf ein Krankenhaus-Tag anstatt auf relevante Lungenregionen zurückgreifen. Bei autonomen Fahrassistenzsystemen könnte ein Algorithmus Verkehrsschilder aufgrund irrelevanter Hintergrundmuster falsch klassifizieren.
Die Verfolgung und Minderung dieser unbeabsichtigten Abkürzungen früh im KI-Entwicklungsprozess ist entscheidend für eine vertrauenswürdige Entwicklung. Werkzeuge wie LRP spielen eine wichtige Rolle im Rahmen der KI-Absicherung, indem sie potenzielle Probleme hervorheben, die weiter untersucht und behoben werden müssen.
SHapley Additive exPlanations (SHAP) – Ein vielseitiges Erklärbarkeitswerkzeug
Ein weiteres vielseitig einsatzbares Werkzeug zur Erklärbarkeitsberechnung von KI-Entscheidungen ist SHapley Additive exPlanations (SHAP). SHAP (siehe Paper, Software Repository und die Dokumentation) bietet einen bedeutenden Vorteil: seine Vielseitigkeit erreicht verschiedene KI-Anwendungsfälle, die weit über die Domäne des Maschinellen Sehens hinausgehen, bis hin zu klassischen Anwendungen in der Analyse von Zeitreihen, Texten und sonstigen Eingabe-Domänen.
Die SHAP Repository, das umfangreich online dokumentiert ist (siehe die Dokumentationsseite), ermöglicht eine unkomplizierte Installation und Nutzung in verschiedenen Anwendungen. Betrachten wir ein Beispiel, bei dem SHAP verwendet wird, um ein ResNet50-Bildklassierungsmodell zu erklären. Nachfolgend sieht man einen Code Schnipsel, das den SHAP Partition Explainer Funktion für diesen Zweck verwendet:
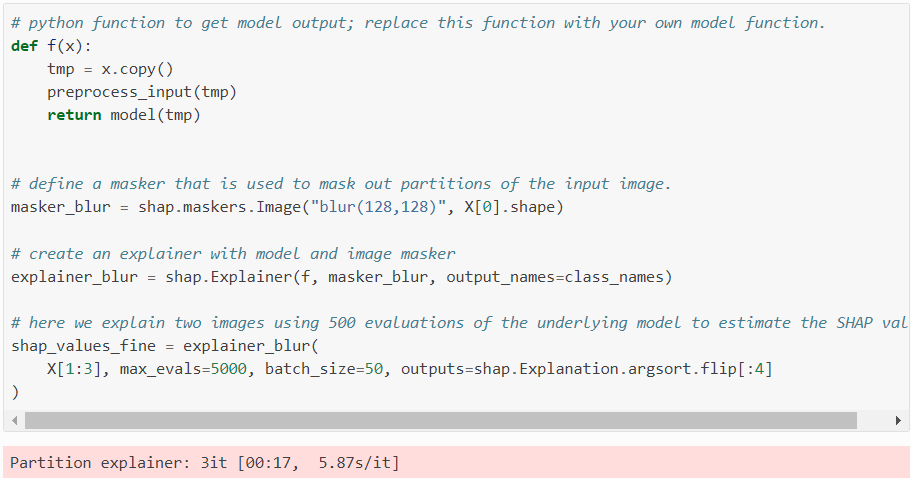
Dann sehen wir unten als Ergebnis die Visualisierung der so berechneten SHAP Werte (SHAP values):
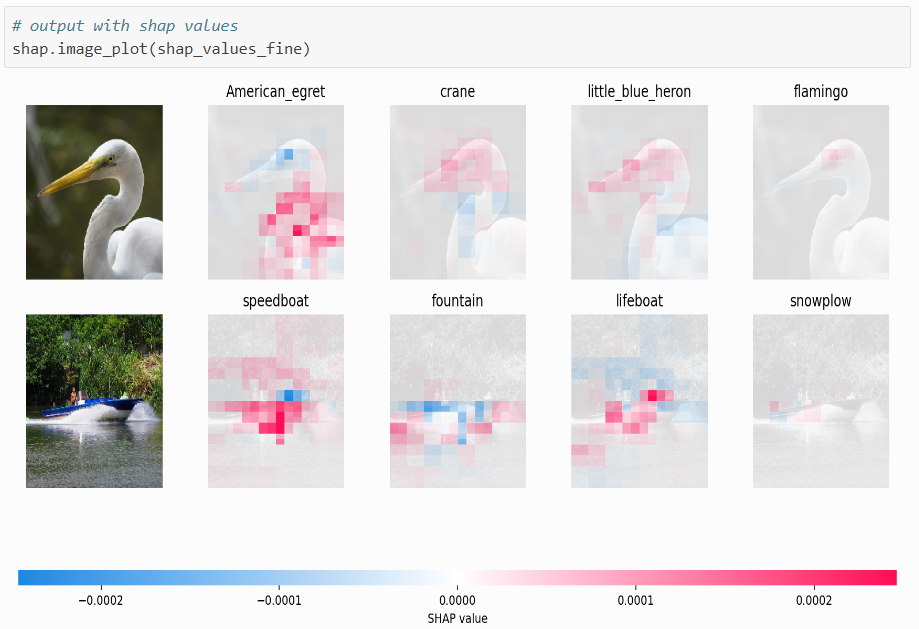
In der generierten Darstellung zeigen rote Pixel positive SHAP-Werte, die die Wahrscheinlichkeit der Klassenprädiktion erhöhen, während blaue Pixel negative SHAP-Werte repräsentieren, welche die Wahrscheinlichkeit der Klassenzugehörigkeit laut Modell reduzieren. Nach der Dokumentationsseite:
- Das erste Bild wird vom Modell als amerikanischer Reiher klassifiziert, beeinflusst durch den „Buckel“ über seinem Hals, wie durch die berechneten SHAP-Werte in diesem Fall hervorgehoben.
- Das zweite Bild wird als Schnellboot klassifiziert, wobei die SHAP-Werte die markante Bootsform hervorheben.
Die breite Anwendbarkeit und laufende Unterstützung von SHAP mit einer permissiven Lizenz machen es zu einer robusten Wahl als KI-Erklärbarkeits-Werkzeug, nicht nur im Bereich des Maschinellen Sehens.
Schlussfolgerung
Werkzeuge wie LRP und SHAP veranschaulichen das Potenzial im Bereich der Entscheidungserklärung. Sie ermöglichen es uns, die Entscheidungsmuster in modernen KI-Algorithmen zu visualisieren und zu verstehen, was wesentlich für die Aufrechterhaltung von Vertrauen und Transparenz ist. Während wir den Schwerpunkt von LRP auf Maschinelles Sehen und die vielseitigen Anwendungen von SHAP hervorgehoben haben, gibt es auch andere ähnliche Werkzeuge, die als kritische Bestandteile eines Rahmenwerks zur kontinuierlichen KI-Absicherung dienen können und das breitere Spektrum der verfügbaren Werkzeuge in diesem Bereich darstellen.
Wekzeuge zur Modelldiagnose
Modelldiagnose versucht, KI/ML-Algorithmen zu entmystifizieren. Traditionelle maschinelle Lernmodelle, wie z.B. logistische Regression oder Support Vector Machines, bieten von Natur aus Transparenz, wodurch ihre Mechanismen leicht interpretierbar sind. Diese Klarheit verschwimmt jedoch, wenn es sich um komplexere Modelle wie TNNs handelt.
Die Information Bottleneck (IB) Theorie des Deep Learning
Trotz der inhärenten Undurchsichtigkeit von TNNs hat das letzte Jahrzehnt eine Welle von erfolgreichen Bemühungen erlebt, die inneren Abläufe sowohl beim Trainieren als auch bei der Inferenz besser zu erklären und verständlich zu machen. Ein wegweisender Beitrag in diesem Bereich ist die Information Bottleneck (IB)-Theorie, welche von Naftali Tishby und seinem Team entwickelt wurde. Verwurzelt in der Informationstheorie, versucht dieser Ansatz, die grundlegenden Mechanismen, welche die Optimierung von TNNs durch das Deep Learning Algorithmus antreiben, zu erklären.
Einführung in die IB-Theorie
Die IB-Theorie postuliert, dass Deep-Learning-Algorithmen die umfangreiche Datenverteilung in eine prägnante Darstellung komprimieren, die eine effiziente Modellinferenz ermöglicht. Sie beruht auf zwei Arten von wechselseitiger Information: einer zwischen den verborgenen Schichten eines TNN und den Eingabedaten und einer anderen, die die verborgenen Schichten des TNN mit der Ausgabe des Modells verbindet.
Laut IB-Theorie umfasst Deep Learning einen zweiphasigen Prozess: eine anfängliche Anreicherungsphase, in der das Netzwerk erhebliche Informationen aus Eingaben und der Ausgabe aufnimmt, gefolgt von einer Kompressionsphase, in der die Informationen aus den Eingabedaten minimiert und die ausgabebezogenen Informationen verstärkt werden. Dieses Theore bietet eine überzeugende Erklärung für den Deep-Learning-Prozess und beleuchtet Phänomene wie Shortcut-Lernen.
Weitere Forschung zur IB-Theorie
Während die IB-Theorie vielversprechend ist, bleibt sie Gegenstand laufender Debatten und Verfeinerungen. Seit ihrer Einführung hat sie weitere Forschungen, Diskussionen und kritische Untersuchungen angeregt. Wissenschaftliche Publikationen zur IB-Theorie (IB paper 1 and IB paper 2) wurden sowohl untersucht als auch erweitert, wie z. B. durch kritische Arbeiten (siehe kritisches Paper zu IB) und weitere explorative Forschungen, einschließlich variationaler Annäherungen von Alexander Alemi und Kollegen (siehe Deep VIB paper) und sehr kürzlich eine Arbeit, welche einen Rahmenwerk zur IB-Analyse vorstellt (siehe Rahmenwerk zur IB Analyse).
Eine schöne und überzeugende Darstellung des IB-Mechanismus wird in der folgenden Abbildung gezeigt, die einem Artikel aus dem Quanta Magazine entnommen ist.
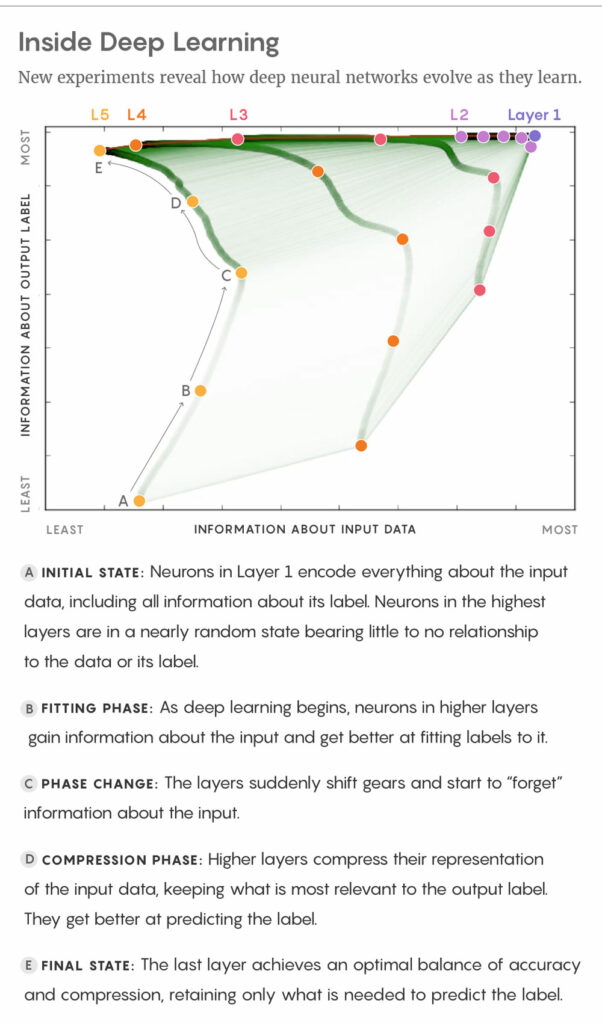
FITTING PHASE: Zu Beginn des Deep Learning gewinnen die Neuronen in den höheren Schichten Informationen über die Eingaben und können diese immer besser beschriften.
PHASE CHANGE: Die Schichten schalten plötzlich einen Gang zurück und beginnen, Informationen über den Input zu „vergessen“.
COMPRESSION PHASE: Höhere Schichten komprimieren ihre Darstellung der Eingabedaten, wobei sie das behalten, was für die Ausgabebezeichnung am relevantesten ist. Sie werden besser bei der Vorhersage des Labels.
FINAL STATE: Die letzte Schicht sorgt für ein optimales Gleichgewicht zwischen Genauigkeit und Komprimierung, indem sie nur das speichert, was für die Vorhersage des Etiketts erforderlich ist.
Obwohl die Entwicklung der IB-Theorie und verwandter Forschungen ein operatives Rahmenwerk verspricht, das möglicherweise integral für die KI-Absicherung ist, suchen wir weiterhin nach etablierteren Werkzeugen, die sofort anwendbar sind. Nichtsdestotrotz können diejenigen, die tiefer in die IB-Theorie einsteigen möchten, in einem zweiteiligen Blog nachlesen, den ich vor einigen Jahren geschrieben habe (Teil 1, Teil 2).
WeightWatcher (WW) – Ein vielseitiges TNN-Diagnosewekrzeug
Ein solch vielversprechendes Werkzeug ist WeightWatcher (WW), entwickelt für die diagnostische Analyse von TNN. Detailliert in einem Nature Communications paper bietet WW eine umfassende Reihe von Funktionen, ohne dass für die Analyse auf Daten (Trining oder Test) zugegriffen werden muss. Laut der GitHub Seite von WW umfassen einige Funktionen:
- Analyse von trainierten Modellen über verschiedene “Frameworks” hinweg (z.B. TensorFlow, Pytorch).
- Überwachung der Leistung des gesamten Modells und jeder Modellschicht, um unter- oder übertrainierte Zustände zu untersuchen.
- Vorhersage von Testgenauigkeiten über verschiedene Modelle hinweg, entweder unter Verwendung von Daten oder ohne Daten.
- Erkennung potenzieller Probleme nach Kompression oder Feinabstimmung vortrainierter Modelle.
- Und mehr.
Das Werkzeug kann einfach in einer Python-Umgebung über pip installiert werden:

Nachfolgend ein einfaches Beispiel fpr die Verwendung von WW in Python:

In diesem Beispiel wird nach dem Importieren von WW und PyTorch-Vision-Modellen (Zeile 1 und 2) das vortrainierte VGG 19-Modell geladen (Zeile 4). Das WW-Modul analysiert dann das Modell (Zeile 5) und fasst die Ergebnisse für das Modell und die einzelnen Schichten des Modells zusammen (Zeile 7).
Nachfolgend sehen wir eine Beispiel-Detailtabelle, die alle WW-Parameter pro Modellsicht zeigt:
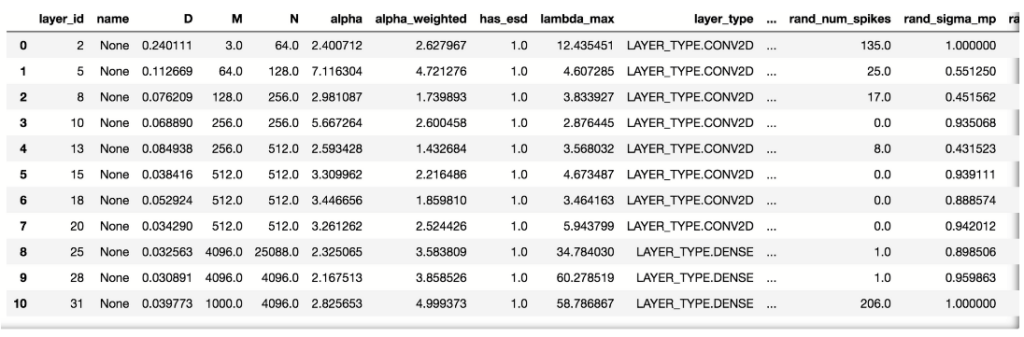
Diese Tabelle ist eine umfangreiche quantitative Dokumentation der Leistung für jede Modellsicht. Wir werden nicht tief in die technischen Details jedes Parameters der Tabelle eintauchen. Diese Details können in den Publikationen zu WW oder den Dokumentationsseiten des Werkzeugs gefunden werden.
Ebenso enthält das Summary-Objekt ein Python-Wörterbuch mit den wichtigsten WW-Analyseparametern:

Sowohl das Summary-Objekt als auch die Tabelle enthalten einen Schlüsselparameter von WW, nämlich den „Alpha“-Parameter, der maßgeblich zur Bewertung der Trainingsqualität für das gesamte Modell (Summary) oder jede Schicht (Detailtabelle) ist. Nach der Theorie deutet ein Alpha-Wert zwischen 2 und 6 auf gut trainierte Schichten hin, Werte über 6 signalisieren Untertraining, und Werte unter 2 signalisieren Übertraining.
Die Empirical Spectral Density, kurz ESD
Zusätzlich gibt WW qualitative Plots wie die „Empirical Spectral Density“ (ESD) für jede Modellsicht aus. Die ESD ist ein Histogramm der Eigenwerte aus der Korrelationsmatrix jeder Schicht nimmt, wobei der Alpha-Parameter aus der Anpassung eines Potenzgesetzes an das Ende dieser ESDs abgeleitet wird. Nachfolgend ein Beispiel für einen ESD-Plot in logarithmisch-logarithmischer Skala (links) und linear-linear Skala (rechts):
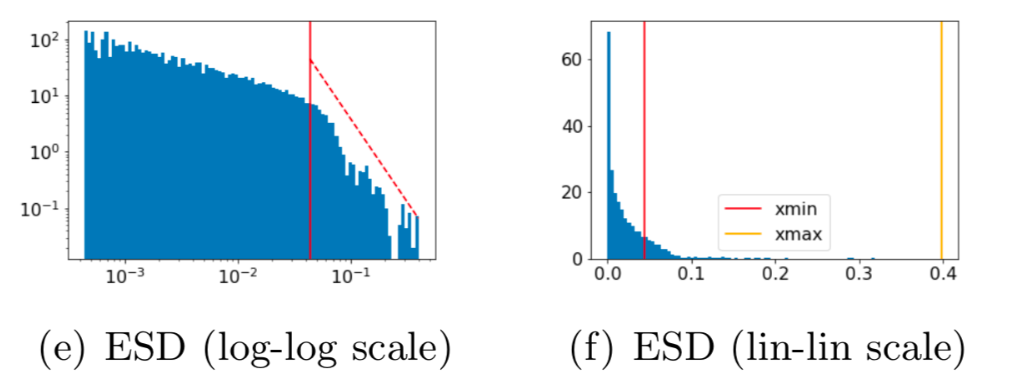
Ein wesentliches Indiz für eine gut trainierte Modellsicht wird in dieser ESD-Stichprobe durch die gute Anpassung des Potenzgesetzes an den ESD (rote gestrichelte Linie im linken Panel) auf der einen Seite und durch die weite Trennung zwischen den minimalen und maximalen Eigenwerten (jeweils die roten und gelben vertikalen Linien im rechten Panel der obigen Abbildung) auf der anderen Seite gezeigt.
Die Überwachung des Alpha-Werts
Der WW-Alpha-Metrik kann auch genutzt werden, um den Modelltrainingsprozess zu verfolgen. Die Überwachung des Alpha-Werts kann ein frühzeitiges Stoppen des Trainingsprozesses ermöglichen, wenn der Alpha-Wert unter 2 fällt. Ein Beispiel für eine solche Überwachung des Alpha-Werts wird nachfolgend zusammen mit den sonst immer zu überwachenden Metriken (Training- und Test-Loss) gezeigt:
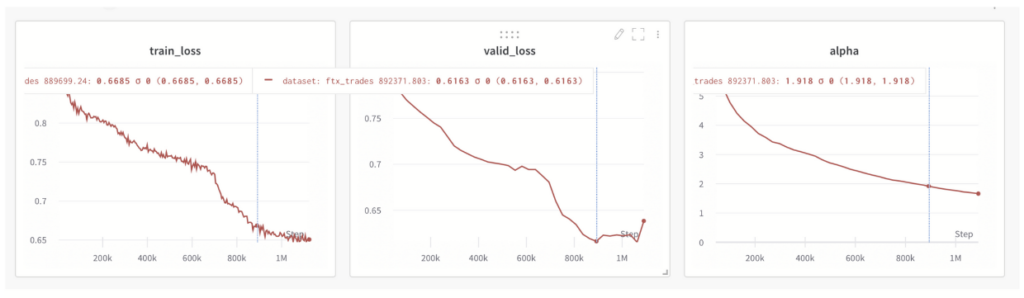
Hier kann man beobachten, dass Alpha im Einklang mit den Trainings- und Test-Loss fällt. Wenn jedoch der Test-Loss die Sättigung erreicht, fällt Alpha unter den Wert von 2.
Schlussfolgerung
Die diskutierten Werkzeuge – von theoretischen Rahmenwerken wie der IB-Theorie bis hin zu praktischen Diagnosewerkzeugen wie WW – bilden Eckfeiler für ein besseres Verständnis der inneren Abläufe von KI -Modellen. Diese Werkzeuge sind entscheidend, um sicherzustellen, dass TNNs trotz ihrer Komplexität zuverlässig bewertet und verbessert werden können. Während wir diese Methoden weiter verfeinern, werden sie zunehmend den vertrauenswürdigen Einsatz komplexer KI-Systeme erleichtern.
Ausblick
Nachdem wir das Spektrum der Diagnosebewertungswerkzeuge für KI, insbesondere SHAP (SHapley Additive exPlanations) und WeightWatcher (WW), untersucht haben, haben wir das Fundament gelegt, um ihre Funktionen und Potenziale zur Verbesserung der sicheren und vertrauenswürdigen KI-Entwicklung innerhalb eines Rahmens für KI-Absicherung zu verstehen. SHAP zeichnet sich durch universelle Anwendbarkeit auf verschiedene maschinelle Lernmodelle aus, indem es Konzepte aus der Spieltheorie nutzt, um lokale Erklärungen für Modellvorhersagen zu liefern. WeightWatcher hingegen bietet eine schichtweise Analyse neuronaler Netzwerke, die unter anderem Einblicke darüber bietet, ob die Netzwerkschichten übertrainiert, untertrainiert oder optimal parametriert sind.
Weitere Forschungsthemen
In einem kommenden Beitrag werden wir tiefer in die praktischen Anwendungen dieser Werkzeuge in sicherheitskritischen Bereichen eintauchen – autonomes Fahren und medizinische Diagnostik. Wir werden speziell die Anwendung von SHAP und WeightWatcher auf die Verkehrsschilderkennung für autonome Fahrzeuge demonstrieren, eine Aufgabe, die entscheidend für die Sicherheit und Zuverlässigkeit selbstfahrender Technologien ist.
Darüber hinaus werden wir den Einsatz dieser Werkzeuge zur Erkennung von Lungenentzündungen in Röntgenbildern untersuchen und ihre Fähigkeiten in der Medizin demonstrieren, wo die Präzision und Zuverlässigkeit von KI-Modellen die Patientenergebnisse erheblich beeinflussen kann.
Author info
