

Noch vor ein paar Jahren hätte der Titel dieses Artikels nicht nur provokativ, sondern eher nach Mission Impossible geklungen (allerdings, ohne dass am Ende jemand die Welt rettet). Viele Infrastruktur- und Servicebetreiber können sich vielleicht noch an Zeiten erinnern, als es nicht überraschend war, um 3:00 Uhr morgens angerufen zu werden, um einen abgestürzten Server oder eine abgestürzte Anwendung wiederherzustellen. Dabei würden viele zustimmen, dass dies alles andere als optimal ist. Abgesehen von unruhigen Betreibern verlieren Kunden, die kritische Serviceunterbrechungen erleben, oft das Vertrauen in versprochene Service Level Agreements. Und unzufriedene Kunden gehören möglicherweise bald überhaupt nicht mehr zu Ihren Kunden.
Aber die Dinge müssen nicht unbedingt so sein. In diesem Artikel werden wir uns ansehen:
- was GitOps ist,
- warum Sie Ihren Betrieb darauf aufbauen sollten,
- und wie Sie damit kontinuierlich selbstheilende, Cloud-native Infrastruktur und Dienste bereitstellen können.
Was ist GitOps und warum verändert es eine ganze Branche in Bezug darauf, wie Infrastruktur und Anwendungen bereitgestellt, verwaltet und wiederhergestellt werden?
GitOps, eingeführt von Alexis Richardson im Jahr 2017, ist eine Art der Anwendungsbereitstellung und des Kubernetes-Cluster-Managements. Der Mechanismus nutzt das bekannte Quellcodeverwaltungssystem Git als Single Source of Truth für deklarative Anwendungen und Infrastruktur. Seine Erfinder beschreiben es als einen Weg zu mehr Entwicklererfahrung für die Verwaltung von Anwendungen und Infrastruktur: „Wo End-to-End-CI/CD-Pipelines und Git-Workflows sowohl auf den Betrieb als auch auf die Entwicklung angewendet werden“.
Das zugrunde liegende Prinzip von GitOps ist ein Git-Repository, dass die deklarative Konfiguration von Anwendungen und/oder Infrastruktur enthält, die derzeit in der Produktions- oder einer anderen Umgebung gewünscht wird. Darüber hinaus sorgt ein automatisierter Prozess permanent dafür, dass der im Git-Repository beschriebene Soll-Zustand mit dem Ist-Zustand der Produktionsumgebung übereinstimmt. Das heißt, wenn Sie eine neue Anwendung bereitstellen oder eine vorhandene aktualisieren möchten, müssen Sie lediglich das Git-Repository aktualisieren – der automatisierte Prozess erledigt den Rest.
Um GitOps zu erreichen, müssen vier Prinzipien gelten.

Die vier Prinzipien von GitOps
Bevor wir uns mit den einzelnen Prinzipien befassen, bedenken Sie, dass es sich per Definition um Prinzipien und nicht um spezifische Technologien handelt. Sie müssen nicht unbedingt alle Ihre vorhandenen Tools ersetzen, sondern können einige davon weiterhin nutzen, zumindest wenn sie mit Git funktionieren (was Sie wahrscheinlich verwenden, oder?).
Prinzip 1: Das gesamte System wird deklarativ beschrieben
SQL hat es geschafft, HTML hat es geschafft und Kubernetes auch. Deklarativ bedeutet, dass eine bestimmte Konfiguration durch eine Reihe von Fakten statt durch Anweisungen garantiert wird. Anweisungen werden normalerweise mit Sprachen wie Java oder Python programmiert, was oft eine steilere Lernkurve erfordert. In der Zwischenzeit teilt die einfache SQL-Abfrage SELECT Kunden-ID, Umsatz FROM Kunde dem Datenbankverwaltungssystem nur mit, was wir wollen, z. B. den Kunden zu finden, der den höchsten Umsatz generiert, ohne eine Reihe von Anweisungen zu geben, wie dies zu tun ist. Das Erreichen des deklarierten Ergebnisses hängt ausschließlich von der Datenbank-Engine ab – oder in unserem Fall von Anwendungen und Infrastruktur: von Kubernetes. Ein wichtiger Vorteil davon ist die sogenannte Idempotenz, d.h. es spielt keine Rolle, wie oft Sie Ihren gewünschten Zustand durch Ausführen des Automatisierungsprozesses erklären/deklarieren. Wenn Sie dem Kubernetes mitteilen, dass immer 5 Server ausgeführt werden sollen, werden 2 Server hinzugefügt, wenn derzeit nur 3 ausgeführt werden, oder 1 Server entfernt, wenn 6 ausgeführt werden. In der Zwischenzeit würde es aufgrund der Idempotenz nichts bringen, wenn Ihr gewünschter Zustand von 5 Servern mit der Realität übereinstimmt – da dies bereits genau das ist, was Sie wollen. Stellen Sie sich vor, Sie geben ansonsten einfach die nicht-deklarative Anweisung „Jetzt 2 Server entfernen“, um nach einem Traffic-Höchststand Ihres Webshops herunterzuskalieren. Was wäre, wenn jemand vor Ihnen bereits von 4 auf 2 Server herunterskaliert hätte? Na ja, … Sie werden es dieses Mal wahrscheinlich nicht zum „Mitarbeiter des Monats“ schaffen. Offensichtlich sind deklarative Systeme in solchen Szenarien vorteilhaft.
Prinzip 2: Der kanonische Soll-Systemzustand wird in Git versioniert
Wenn die Deklaration Ihres Systems in Git gespeichert ist, das als Single Source of Truth dient, können Ihre Anwendungen problemlos von und nach Kubernetes bereitgestellt und zurückgesetzt werden. Das Git-Protokoll – das zeigt, wann und von wem jede einzelne Konfigurations-/Codezeile geändert wurde – macht Rollbacks für die Notfallwiederherstellung mit einem Klick möglich. Ihre Produktionsumgebung ist ausgefallen? Mit GitOps haben Sie ein vollständiges Protokoll darüber, wie sich Ihre Umgebung im Laufe der Zeit verändert hat. Ein Einfaches „Git-Revert“ ermöglicht es, zu Ihrem vorherigen (fehlerfreien) Anwendungsstatus oder zu jedem anderen Snapshot zurückzukehren.
Prinzip 3: Genehmigte Änderungen können automatisch auf das System angewendet werden
Sobald Sie den Status in Git deklariert haben, besteht der nächste Schritt darin, zuzulassen, dass alle Änderungen an diesem Status automatisch auf Ihr System angewendet werden. Ein wichtiger Vorteil davon ist, dass das deklarative Zustandsrepository nicht unbedingt neben dem eigentlichen Code des Systems gespeichert werden muss. Diese Trennung von Anwendungs-/Infrastrukturcode von Konfigurations- und Bereitstellungscode trennt effektiv, was Sie tun, und wie Sie es tun. Darüber hinaus verbessert es die Gesamtsicherheit des Systems, da Entwickler oft nur auf das Anwendungscode-Repository zugreifen müssen. In der Zwischenzeit können Geheimnisse und Passwörter aus dem anderen Repository in die Bereitstellungspipeline eingefügt werden – auf die möglicherweise nur das Betriebsteam zugreifen kann. Und wenn alles über Git verwaltet wird, warum nicht ein Vier-Augen-Prinzip für den Betrieb durchsetzen, indem Prozesse genutzt werden, die bereits Geschichte geschrieben haben? Nehmen wir als Beispiel den guten alten Pull Request. Nach dem Durchlaufen einer Pipeline, die nach Fehlkonfigurationen und Schwachstellen sucht, bevor die automatisierte Bereitstellungspipeline gestartet wird, muss sie zunächst von mindestens einem anderen Mitglied des Betriebsteams genehmigt werden. GitOps bietet ein Audit- und Transaktionsprotokoll für alle am System vorgenommenen Änderungen sowie die Möglichkeit, jede von ihnen entlang der Zeitachse zu überprüfen. Daher ist es viel schwieriger, von Anfang an etwas zu vermasseln, wenn es zusammen mit Entwicklungsprozessen wie „Operations by Pull Request“ verwendet wird.
Prinzip 4: Software-Agenten sorgen für Korrektheit und Alarmbereitschaft (Diffs & Actions)
Durch die kontinuierliche Überwachung des Git-Repositorys als Source of Truth können Softwareagenten einen informieren, wenn die Realität nicht den Erwartungen entspricht. Darüber hinaus können solche Mittel auch für eine Selbstheilung des Systems sorgen. Dies beschränkt sich nicht nur auf gelegentlich abstürzende Server, sondern auch auf menschliche Fehler. Jemand hat eine der Web-UIs von AWS, Azure oder GCP verwendet, um versehentlich eine Firewall-Regel zu löschen? Ein Software-Agent kann den Ist- mit dem Soll-Zustand vergleichen, diesen Fehler erkennen und anschließend korrigieren, indem er die gelöschte Regel (erneut) anwendet. In unserem Fall könnte die Firewall durch Infrastructure as Code beschrieben werden, das anbieterunabhängige Tool Crossplane ist ein beliebtes Beispiel, um dies über verschiedene Anbieter hinweg zu ermöglichen. Solange jemand dem System gesagt hat, dass es Firewalls geben könnte, werden deklarative GitOps dafür sorgen, dass sie es sind, auch wenn etwas schief gegangen ist. Dies geschieht normalerweise durch Abfragen des Git-Repositorys alle paar Minuten, um den gewünschten Zustand zu erhalten, sowie durch Abgleichen des tatsächlichen Clusterzustands zur Abweichungserkennung und -korrektur. Schließlich sind solche Kontrollagenten genau der Grund, warum viele Operation Engineers heutzutage viel ruhiger schlafen, und ich nehme an, viele ihrer Kunden auch.
Nachdem wir gelernt haben, was die vier Prinzipien von GitOps sind und warum sie wichtig sind, schauen wir uns an, wie dies in die Praxis umgesetzt werden kann!
Wie funktioniert GitOps, um Cloud-native Infrastruktur und Dienste kontinuierlich bereitzustellen, zu betreiben und wiederherzustellen?
In den letzten Jahren haben sich einige Best Practices herauskristallisiert, also denken Sie an Folgendes, wenn Sie Ihre GitOps-Reise beginnen:
Umgebungskonfigurationen als separates Git-Repository
Bei GitOps ist der gesamte Bereitstellungsprozess um ein zentrales Code-Repository herum organisiert. Normalerweise sollten zwei Repositorys vorhanden sein: das Anwendungs-Repository und das Umgebungskonfigurations-Repository. Das Anwendungs-Repository enthält sowohl den Quellcode Ihres Dienstes als auch die (Kubernetes-)Manifestvorlagen für die Bereitstellung der Anwendung. Das Umgebungskonfigurations-Repository enthält die tatsächlichen Werte für die Bereitstellungsmanifestvorlagen des aktuell gewünschten Infrastrukturzustands. Das heißt, es beschreibt, welche Anwendungen und Infrastrukturdienste (Service Mesh, Datenbanken, Logging- und Monitoring-Tools etc.) mit welcher Konfiguration in der Deployment-Umgebung laufen sollen. Vielleicht möchten Sie Ihre analytische Datenbank in der Entwicklungsumgebung mit einer anderen Version als QA testen oder Ihre Backend-Microservices für eine hohe Verfügbarkeit in der Produktionsumgebung immer auf mindestens drei Replikate skalieren lassen. Alle diese für jede Umgebung spezifischen Konfigurationen sollten im Umgebungs-Repository gespeichert werden. Helm ist ein gutes Beispiel für ein Tool, das häufig für Kubernetes-Konfigurationsvorlagen verwendet wird. Darüber hinaus ist das Durchführen von Rollbacks und das Durchsuchen des Git-Verlaufs mit einem Repository für jede Entwicklung und jeden Vorgang deutlich einfacher.
Pull-basierte Bereitstellungen
CI/CD-Pipelines werden traditionell durch ein bestimmtes Ereignis ausgelöst, beispielsweise wenn Code in ein Anwendungs-Repository übertragen wird. Bei der Nutzung des Pull-basierten Bereitstellungsansatzes wird das sogenannte Operator Pattern eingeführt. Grundsätzlich ist ein Bediener kodifiziertes betriebliches Wissen. Es übernimmt den CD-Teil der CI/CD-Pipeline, indem es kontinuierlich den Ist-Zustand in der bereitgestellten Infrastruktur mit dem Soll-Zustand im Umgebungs-Repository vergleicht. Wenn er einen Unterschied feststellt, wird der Operator die Infrastruktur automatisch abgleichen, so dass sie (wieder) mit dem Umgebungs-Repository übereinstimmt. Außerdem kann die Registrierung der Anwendungsimages überwacht werden, um zu prüfen, ob neue Versionen von Images bereitgestellt werden können.
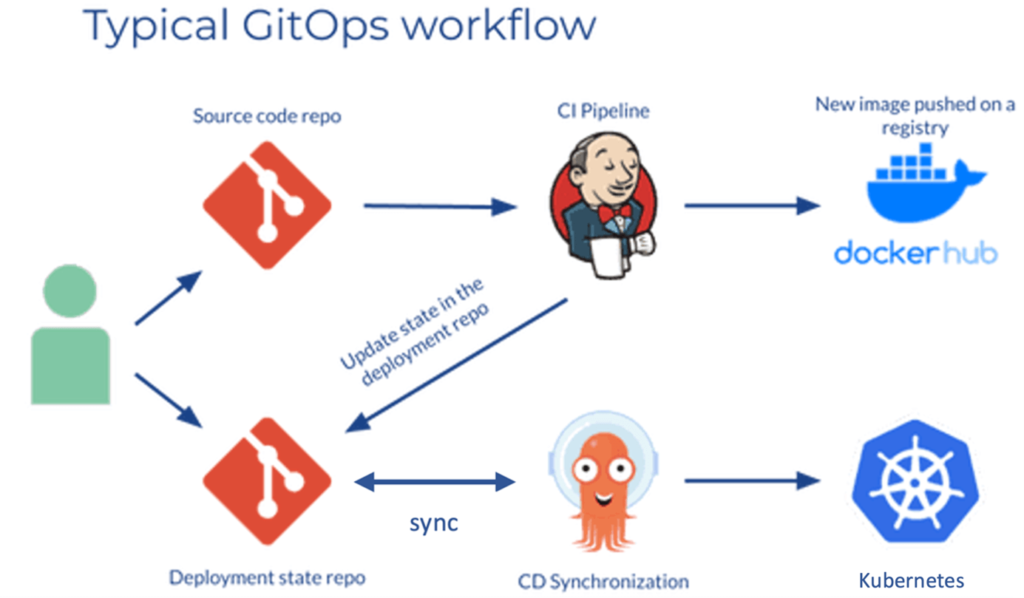
Genau wie Push-basierte Bereitstellungen, die traditionell mit Pipeline-Tools wie Jenkins oder Github Actions durchgeführt werden, ändern Pull-basierte Bereitstellungen die Umgebung, wenn sich das zugrunde liegende Umgebungs-Repository ändert. Ein Operator erkennt jedoch Änderungen gegenseitig. Zum Beispiel, wenn Ihr neuer Praktikant ausprobiert, was passiert, wenn Sie einen dieser vielen verwirrenden Kubernetes-Namespaces löschen – versehentlich Ihr Produktions-Backend löschen. Wenn sich Ihr bereitgestellter Dienst oder Ihre Infrastruktur in irgendeiner Weise ändert, die nicht im Umgebungs-Repository beschrieben ist, werden diese Änderungen automatisch rückgängig gemacht, wobei in unserem Beispiel der Namespace und alle Produktions-Back-End-Dienste neu erstellt werden.
Im Vergleich dazu aktualisieren herkömmliche Push-basierte CI/CD-Methoden die Umgebung nur, wenn das zugrunde liegende Konfigurations-Repository aktualisiert wird – was häufig zu einem blinden Fleck zwischen diesen Aktualisierungen führt. Vergessen Sie jedoch nicht, Ihren Bereitstellungsoperator zu überwachen, da Sie ohne ihn jetzt überhaupt keine automatisierte Bereitstellung mehr haben.
Abschließender Gedanke
GitOps verändert grundlegend die Art und Weise, wie Dinge betrieben werden. Wenn wir es ernst nehmen, würde ich argumentieren, dass wir ein neues Muster einführen sollten, um unsere Probleme zu lösen: Everything-as-Code.
Stellen Sie sich vor, dass nicht nur Ihre Anwendungen und Infrastruktur, sondern buchstäblich alle Konfigurationen, Sicherheitsrichtlinien, Protokollierungen, Überwachungen und Alarmierungen sowie fortschrittliche Rollout-Strategien wie Canary-Bereitstellungen in Git gespeichert und automatisiert werden – was es möglich macht von nichts zu einem produktiven, hochverfügbaren und sicheren Dienst zu kommen, selbst wenn es zu einem Disaster kommen sollte. Die Chancen stehen gut, dass Sie ruhiger schlafen können.