Wie alles begann
Du kennst Large Language Models, kurz LLMs… Sie sind quasi die neue Elektrizität. Elektrizität fließt fast so schnell wie Licht – so schnell, dass wir kaum begreifen können, was sie ist oder wie sie uns helfen kann. Und sobald du denkst, du hast verstanden, wie das alles funktioniert, merkst du, dass LLMs bereits viel weiter sind.
Suchmaschinen, Chats, E-Commerce, Ticketsysteme, Coden, kreative Tätigkeiten und zahlreiche intelligente Automatisierungen werden mittlerweile von LLMs gesteuert – von Modellen, die sich wie echte Menschen verhalten können. Sie verstehen unstrukturierte Daten. Die Daten, von denen wir vor 2–3 Jahren noch dachten, dass nur Menschen sie interpretieren können.
Generative KI… nur zum Spaß?
Ich bin Data Scientist und muss gestehen: Generative KI wie LLMs fand ich anfangs nicht besonders spannend. Ich hielt sie für ein nettes, etwas seltsames Experiment, das höchstens unterhaltsam war.
Heute weiß ich: Generative KI wird ein Partner für den Menschen sein – sie wird Effizienz steigern, Abläufe optimieren und schnelle Ergebnisse liefern, ganz egal in welchem Bereich. Wahrscheinlich wird sie unser neuer Arbeitskollege – der, der in allem Experte ist. Aber unterschätzen wir die Menschen nicht.
Mit Data Chat erkunde ich, wie ein LLM funktioniert, welche Möglichkeiten es in meinem Fachbereich bietet und wie wenig Informationen es benötigt, um dennoch gute Antworten zu liefern.
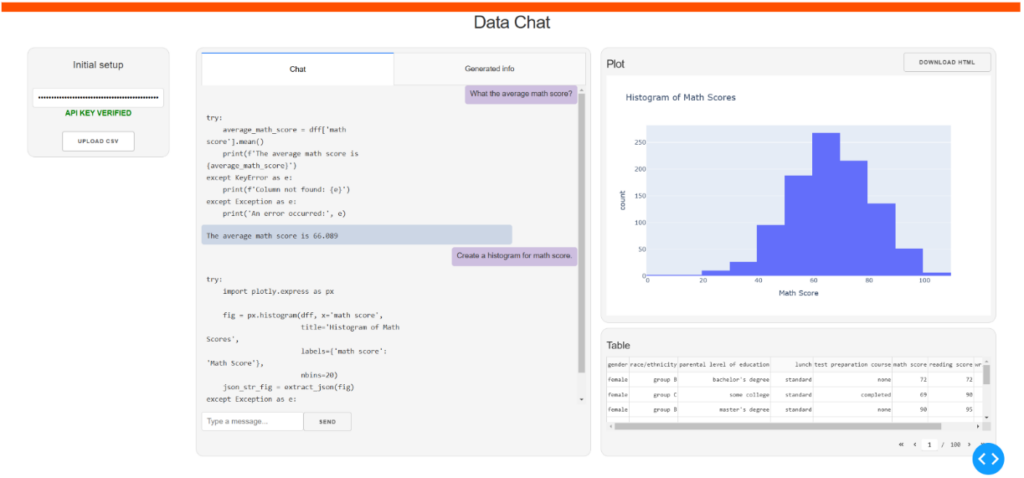
Was ist Data Chat?
Data Chat ist ein Partner für alle User, die Informationen aus einer CSV-Datei extrahieren sowie schnelle Einblicke, Statistiken und Diagramme generieren möchten. Eine CSV-Datei (kurz für Comma Separated Values) enthält Daten, bei denen die einzelnen Werte jeweils durch ein Komma getrennt sind.
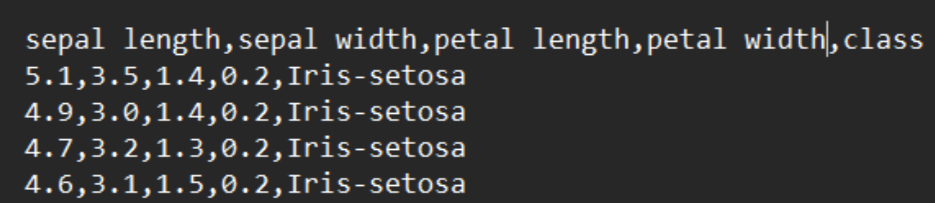
Superwichtig: Data Chat kann auch bestehende Spalten bearbeiten und neue Spalten in Echtzeit erstellen. Klingt nach Feature Engineering, oder?
Die Kommunikation mit Data Chat
Data Chat ist eine einfache Data-Analytics-Lösung, die keine Erfahrung in diesem Bereich voraussetzt. Die Idee ist ganz simpel: Stelle eine Frage und Data Chat antwortet. Die Frage muss nicht fachmännisch formuliert sein, in den meisten Fällen versteht Data Chat, was gemeint ist.
Die Arbeit mit Data Chat ist ein interaktiver Prozess. Der User stellt eine Frage, Data Chat antwortet. Falls die Antwort nicht die erwartete ist oder unvollständig erscheint, kann der User die Frage verfeinern oder weitere Details hinzufügen. Ganz ähnlich zu dem, wie man eben auch mit einer echten Person interagiert.

Warum Data Chat?
Natürlich gibt es andere Tools, die Ähnliches können. Zudem verfügen etablierte Lösungen wie Power BI oder Excel über einen integrierten Copiloten. Selbst OpenAI bietet eine Funktion namens Assistant, bei der ein Dokument hochgeladen werden kann. Anschließend kann das Modell dieses Dokument zusammenfassen, wichtige Informationen herausfiltern, Diagramme generieren, korrigieren oder verbessern.
Aber wer eines dieser Tools nutzt, gibt die Vertraulichkeit der Daten auf. Das Modell muss die Daten sehen, bevor es Antworten generieren kann.
Data Chat hingegen kann Erkenntnisse aus einer CSV-Datei ableiten, ohne die eigentlichen Daten einzusehen. Lediglich die Kopfzeile der Tabelle und die Datentypen werden zusammen mit der Userfrage übermittelt.
Der Datenfluss
Hier nochmal eine kurze Zusammenfassung der Funktionsweise der Antwortgenerierung.
Von Anfang an benötigt der User zwei Dinge:
- Eine CSV-Datei als Datenquelle.
- Einen OpenAI API Key. Data Chat liefert Antworten mit Hilfe von „gpt-4o“.
Sobald der API Key verifiziert und die Datei hochgeladen wurde, kann die Arbeit beginnen:
- Der User stellt eine Frage.
- Die Frage wird zusammen mit einem Prompt, den Spaltennamen und den Spaltentypen an das Modell gesendet.
- Das Modell gibt eine Antwort im JSON-Format zurück. JSON ist ein Dateiformat, das Daten als Namen-Wert-Paare speichert (z. B. {“user”: “Hello!”, “assistant”: “Nice to meet you!”}). Lasst uns annehmen, dass die Antwort gültig ist.
- Die JSON-Antwort wird überprüft und verarbeitet, um sicherzustellen, dass sie korrekt formatiert ist.
- Aus dem JSON wird der Python-Code extrahiert und ausgeführt.
- Das Ergebnis kann eine dieser drei Formen annehmen:
1) Ein Text mit Informationen; es kann auch eine Fehlermeldung auftreten.
2) Ein Diagramm oder eine Grafik.
3) Eine Änderung an der ursprünglich hochgeladenen Tabelle. - Abhängig vom Ergebnis wird die entsprechende Anzeige im Dashboard aktualisiert.
- Falls Änderungen an der Tabelle vorgenommen wurden, dient die aktualisierte Version als neue Datenquelle für die nächste Anfrage.
- …und dann das Ganze wiederholen.
Der Tech-Stack
Die Benutzeroberfläche und die Funktionalitäten des Dashboards wurden mit der Python-Bibliothek Dash erstellt.
Zur Datenverarbeitung habe ich Pandas und NumPy verwendet. Pandas ist die meistgenutzte Bibliothek in Python zur Arbeit mit Tabellen, während NumPy schnelle mathematische Berechnungen mit Vektoren und Matrizen ermöglicht. Da Plotly und Dash aus demselben Umfeld stammen, war Plotly die logische Wahl für die Erstellung von Diagrammen. Plotly ist eine Bibliothek für interaktive und erweiterte Visualisierungen, während Dash speziell für Datenanalyse-Dashboards entwickelt wurde.
Zur Interaktion mit „gpt-4o“ ist eine OpenAI-Bibliothek erforderlich. Der Rest basiert auf der Standard-Python-Bibliothek. Dies ist genau das Tech-Stack, das ein Data Scientist im Arbeitsalltag verwendet. Die Neuerung liegt im Einsatz eines LLMs.
Was ich beim nächsten Mal ändern würde
Wer mit LLM-Frameworks vertraut ist, wird sich vielleicht fragen, warum ich kein Framework wie LangChain verwendet habe, um den Prozess zu optimieren. Ich wollte jedoch jeden Schritt genau kontrollieren, um zu verstehen, wie man am besten mit einem LLM arbeitet. Beim nächsten Projekt werde ich dieses Framework aber definitiv nutzen.
Übrigens: Wenn dich LLMs detaillierter interessieren, schau doch mal in diesen Artikel über Pre-training und Fine-tuning von LLMs vorbei!
Highlights von Data Chat
1. Das Design
Du wirst lachen, aber ich habe einen Großteil der Zeit darauf verwendet, das Dashboard von Data Chat optisch ansprechend zu gestalten. Trotz dieser Bemühungen ist das visuelle Ergebnis eher mittelmäßig – meine HTML- und CSS-Kenntnisse sind begrenzt. Stimmst du zu, dass Menschen sich eher für ein Produkt entscheiden, das besser aussieht als für eines, das besser funktioniert?
Wo wir gerade bei der Bedeutung einer guten Visualisierung sind – unsere Kollegin Laura Wiegmann hat sich bereits in ihrem letzten Artikel mit der Visualisierung von Jira-Daten beschäftigt.
2. Prompting
Um das Beste aus dem Modell herauszuholen, muss ein sehr guter Prompt erstellt werden, der klar definiert, was vom Modell erwartet wird, welche Eingaben es gibt, welche Ausgabe benötigt wird, und welche Einschränkungen gelten. Ich habe den Prompt dutzende Male überarbeitet – und entdecke immer noch Möglichkeiten zur Verbesserung.
Ein Tipp: Beispiele sind entscheidend. Am besten für jeden Anwendungsfall ein allgemeines Beispiel geben.
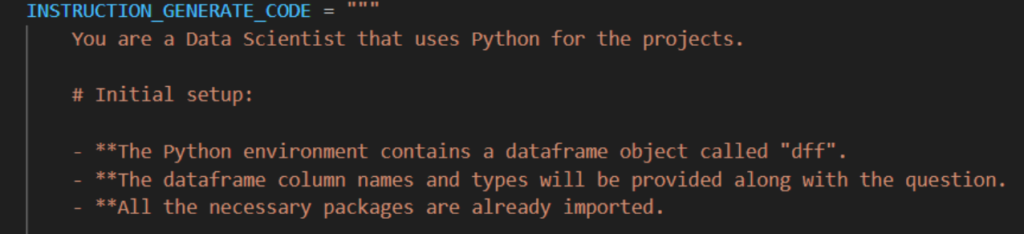
3. Das Formatieren der Antwort
Es kann vorkommen, dass das Format der Antwort nicht korrekt ist, auch wenn es im Prompt konkret beschrieben wurde. Kontrolliere also unbedingt das Format, bevor es weiterverarbeitet wird. Wenn das Modell Code generiert, ist es noch wichtiger, die Antwort zu verifizieren und gegebenenfalls zu korrigieren. Ein Fehler kann bereits durch eine falsche Platzierung eines Leerzeichens im Code auftreten.
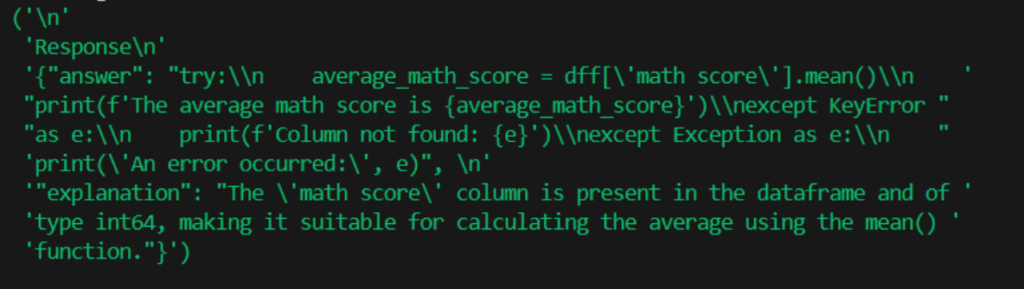
4. Code ausführen
Wie bereits erwähnt, kann das Ergebnis des Codes Text, ein Diagramm oder Änderungen an der Tabelle sein. Einer der schwierigsten Aspekte war es, die Art des Ergebnisses zu bestimmen, damit es an der richtigen Stelle im Dashboard angezeigt wird. Diagramme sind ziemlich tricky, da sie als Text (genauer gesagt als Dictionary) generiert werden. Die Lösung war die Verwendung eines guten alten Regex, der das Diagramm speichert, anstatt es anzuzeigen.
Versetze dich in die User hinein
Was du jetzt gesehen hast, ist die dritte Version des Projekts. Die erste Version funktionierte im Terminal, und ich habe sie meinen Kollegen in Rumänien präsentiert. Um die Präsentation kurz zu halten, hatte ich mögliche Fragen schon im Voraus erstellt.
Eine Kollegin aus der Data-Analytics-Abteilung merkte an, dass die Fragen zu spezifisch und technisch seien. Und sie hatte recht. Ich dachte wie ein Data Scientist aber empfahl das Produkt ja Menschen ohne Erfahrung in diesem Bereich.
Also konzentrierte ich mich darauf, Data Chat so einfach wie möglich zu gestalten. Das Dashboard ist ein Teil dieses Ansatzes und eine neue Funktion entstand: Angenommen, du weißt gerade nicht, welche Informationen du aus den Daten extrahieren sollst. In diesem Fall erstellt Data Chat eine Liste von Fragen, die relevant für deine Daten sein könnten, basierend auf der Tabellenbeschreibung und deinem Ziel. Du kannst dann die Fragen auswählen, die du gut findest, und das Dashboard beantwortet sie daraufhin.
Abschließende Gedanken
Du musst nicht unbedingt Data Chat verwenden, aber ich ermutige dich, die Generative KI zu nutzen, ob zum Spaß oder beim Arbeiten. Man weiß schließlich nie, wann es wirklich relevant für die Arbeit werden könnte.
Außerdem: LLMs erinnern uns daran, wie wir klar und verständlich kommunizieren sollten, andernfalls erhalten wir nicht die erwarteten Ergebnisse. Genau so sollten wir auch als Menschen miteinander kommunizieren.
Author info
