
Data- und AI-Engineering bilden die Grundlage dafür, wie Organisationen intelligente Systeme aufbauen, skalieren und produktiv einsetzen: von der Datenaufnahme und Architektur bis hin zum Deployment von Modellen. Die Erwartungen an Automatisierung, Geschwindigkeit und KI-gestützte Entscheidungsfindung steigen weiter, sodass Engineering-Teams vor Herausforderungen stehen wie:
>>> Welche Plattformen sollten wir wählen, wenn die Optionen immer weiter so rasant zunehmen?
>>> Welche Daten sollten wir wann nutzen?
>>> Wie können wir die Governance über diese komplexen Systeme aufrechterhalten?
Für diesen Artikel haben wir fünf Data- & AI-Engineering-Trends für 2026 ausgewählt, die vielversprechend wirken, zum Nachdenken anregen oder auch kritisch diskutiert werden dürfen. Bereit für die großen Player dieses Jahres im Daten- & KI-Bereich?
1. Multimodale Lakehouses
Mitte 2025 hat LanceDB die Multimodal Lakehouse Suite in sein Enterprise-Angebot integriert und den Begriff Multimodal Lakehouse damit online weit verbreitet. Wir kennen bereits Data Lakes, die verschiedene Arten von Rohdaten zentral speichern. Multimodale Lakehouses gehen einen Schritt weiter und vereinen die Speicherung und Abfrage noch komplexerer Datentypen wie Video, Audio, 3D-Modelle und Embeddings in einem einzigen System. Hier ist das System speziell für KI-native Workflows wie Retrieval-Augmented Generation (RAG) und Model-Training-Pipelines ausgelegt.
Übrigens: Wenn du dein Wissen zu RAG auffrischen möchten, empfehle ich den Artikel meines Kollegen über „Einfache und fortgeschrittene Retrieval Augmented Generation (RAG)“.
Ein wesentlicher Unterschied zu traditionellen Data Lakes liegt darin, wie diese Systeme Medien- und Vektordaten behandeln. Statt sie als sekundäre oder Hilfsdateien zu speichern, gelten sie in multimodalen Lakehouses als Kerninhalte. Die Vektorsuche ist direkt in die Storage Engine integriert. Das macht externe Indizierung (Indexing) überflüssig und erlaubt hybride Abfragen wie „Finde ähnliche Audio-Snippets aus der letzten Stunde“.
Vorteile multimodaler Lakehouses
- Reduzierte Latenz, weil Zero-Copy-Pipelines das Training und Serving aus denselben Rohdaten ohne Duplikation erlauben
- Streaming Updates machen es ideal für dynamische Produktionsumgebungen: Modelle, die deployed wurden, und Dashboards reagieren sofort auf neue Daten und sorgen dafür, dass Vorhersagen und Insights aktuell bleiben, ohne dass Daten manuell neu geladen werden müssen (während ein Retraining bei Bedarf automatisiert werden kann)
- Geringer operativer Aufwand und schnellere Time to Market: Das multimodale Lakehouse bietet AI Engineers einen vereinfachten Zugang zu Rechenressourcen und Datentools, sodass sie sich stärker auf kreative Aufgaben wie Entwicklung und Experimente konzentrieren können statt auf Dateninfrastruktur
Use Cases von multimodalen Lakehouses
- Recommender Systeme: Zur Ableitung von Vektorrepräsentationen aus Nutzerdaten wie Logs und Klicks, um Nearest Neighbour Retrieval zu ermöglichen
- LLM- und KI-Modelltraining: Zur Aufbereitung großer Textsammlungen durch Extraktion, Bereinigung und Einbettung von Daten für den Einsatz in Transformer Modellen und beim Training von KI-Modellen mit gemischten Datentypen
- Semantische Suchmaschinen: Zur Erstellung hybrider Suchworkflows, die Embeddings mit Bildunterschriften, Thumbnails und strukturierten Metadaten kombinieren
Aber: Eine zentralisierte und effiziente Datenverwaltung wird noch entscheidender, wenn sich multimodale KI-Systeme im Jahr 2026 weiter verbreiten.
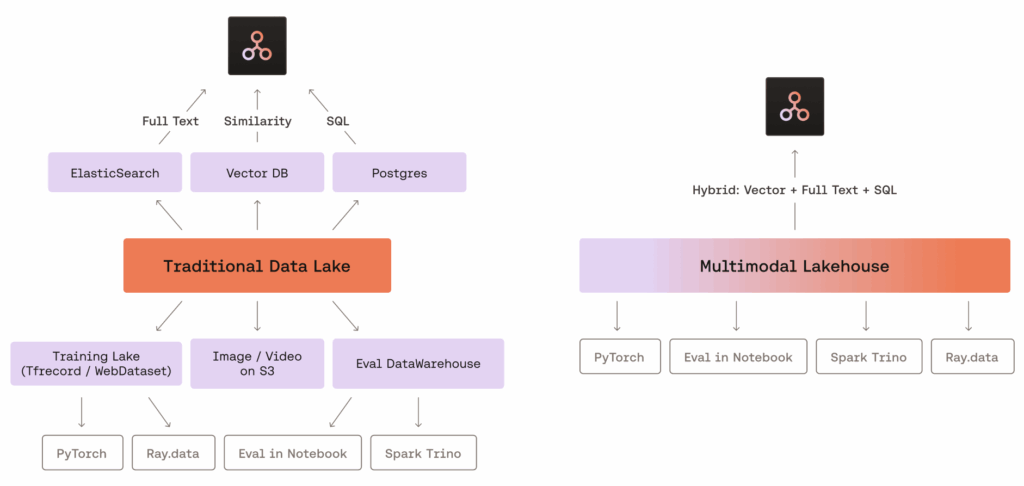
Quelle der Grafik: LanceDB (https://lancedb.com/blog/multimodal-lakehouse/?utm_source=gradientflow&utm_medium=newsletter)
2. Evaluation-Driven Development (EDD)
Der nächste große Trend in 2026 ist Evaluation-Driven Development, kurz EDD. Dieser Ansatz macht Evaluations-Tests, auch „Eval“-Tests genannt, zum Kern von KI- und Datenentwicklung und geht über herkömmliches Unit-Testing hinaus.
Was macht Evaluation-Driven Development also anders
- End-to-End-Fokus: Evals wirken wie End-to-End-Tests für KI- und probabilistische Systeme und bewerten die Ausgabequalität statt einzelner Code-Pfade
- Flexible Bewertung: Sie kombinieren automatisierte Checks, menschliches Urteil und KI-unterstützte Bewertung, um die inhärente Variabilität von KI-Outputs abzubilden
- Kontinuierliche Verbesserung: Durch Integration von Benchmarking, Trend-Analyse und echtem User-Feedback leitet EDD datenbasierte Systemverbesserungen
In der KI-Entwicklung sind Trade-offs gang und gäbe: Die Verbesserung einer Metrik kann eine andere verschlechtern. Hier glänzt EDD und hilft, diese Trade-offs wissenschaftlich zu navigieren: Ähnlich wie bei einer wissenschaftlichen Methode startest du mit einer Hypothese zum erwarteten Verhalten. Experimente und systematische Evaluation bestätigen, widerlegen oder verfeinern deine Annahmen. Dieser Ansatz verhindert, dass KI-Projekte im Proof-of-Concept-Stadium stecken bleiben (theoretisch erfolgreich, aber ohne realen Wert) und fördert iterative, messbare Fortschritte.
Kurz gesagt: Evaluation-Driven Development hilft, Ideen produktiv zu machen und iterativ zu verbessern. In der Praxis von EDD werden Modelle basierend auf systematischer Evaluation verfeinert, nicht nur auf rohen Trainingsdaten. Zum Beispiel kann ein LLM als „Richter“ agieren, um die Relevanz von semantischen Suchergebnissen auf einer Skala von 0 bis 3 zu bewerten, und diese Bewertungen leiten dann Modellverbesserungen in einer iterativen Schleife.
Vorteile von Evaluation-Driven Development (EDD)
- Nachverfolgbarkeit und Reproduzierbarkeit: Versionierte Evaluation-Suites in CI/CD-Pipelines machen Systemänderungen nachvollziehbar und blocken Regressionsfehler
- Trend-Analyse: Teams können Performance über mehrere Läufe hinweg überwachen, statt sich auf einzelne Snapshots zu verlassen
- Robuste Qualitätskontrolle: Besonders entscheidend für komplexe Systeme wie LLMs, RAG-Pipelines, KI-Agenten und große agentische KI-Systeme
Für Teams, die mit modernen KI-Anwendungen arbeiten, wird EDD also schnell zu einer Best Practice für messbare, qualitativ hochwertige Ergebnisse. Und so können Entscheidungen in der Entwicklungsphase weg von intuitivem „Trial-and-Error“-Prompt-Engineering hin zu schnellen Erfolgen verschoben werden. Oder wie Dr. Nimrod Busany, Leiter der Knowledge Engineering & KI Labs an der Tel-Hai University, es treffend in seinem Blogartikel sagt: „The age of “YOLO prompt engineering” is ending. The age of “statistically validated, continuously evaluated, cost-optimized AI systems” has begun.”
3. KI-native Datenplattformen
KI-native Plattformen werden essenziell, um effiziente, intelligente KI-Anwendungen zu bauen. Aber was macht eine Dataplattform eigentlich KI-nativ? Diese Plattformen verlagern den Fokus von reiner Datenverarbeitung hin zu semantischem Verständnis im Businesskontext. Sie sind dafür ausgelegt, sowohl strukturierte als auch unstrukturierte Daten zu handeln, inklusive hochdimensionaler Vektor-Embeddings für Ähnlichkeitssuche und semantisches Retrieval. Um das skalierbar und schnell zu machen, setzen KI-native Dataplattformen auf fortschrittliche Indizierungstechniken wie Approximate Nearest Neighbour (ANN), kombiniert mit GPU-Beschleunigung für schnelle, skalierbare Query-Ausführung.
Hybride Abfragen sind ebenfalls eine starke Stärke: Die Kombination aus vektorbasierter Ähnlichkeitssuche mit strukturierten Filtern ermöglicht kontextbewusste, präzise Ergebnisse. Deshalb sind KI-native Dataplattformen mit zunehmender Bedeutung semantischer Abfragen und wachsendem Datenvolumen eine gute Wahl.
Vorteile KI-nativer Datenplattformen
Was sind also die konkreten Vorteile von KI-nativen Dataplattformen? KI-native Dataplattformen vereinfachen Systemarchitekturen erheblich, indem sie Fähigkeiten bündeln, die früher mehrere spezialisierte Tools erforderten. Gleichzeitig ermöglichen sie Erkenntnisse aus Echtzeit-Analysen, da KI-Fähigkeiten direkt in die Datenbank eingebettet sind. Das vereinfacht RAG-Workflows (Retrieval Augmented Generation) und Tasks im Bereich Machine Learning.
Use Cases für KI-native Datenplattformen
KI-native Datenplattformen glänzen unter anderem in den Bereichen:
- Nahtlose Customer Experience & Personalisierung: Personalisierte Produkt- & Contentempfehlungen, dynamische Preisfindung, konversationelle Analysen für Kundensupport und Verkaufsassistenten (KI-unterstützte Verkaufsassistenten wecken dein Interesse? Dann schau dir mal NEVO an)
- Risiko, Sicherheit & Compliance: Betrugserkennung, Kreditscoring, Risikobewertungen in Echtzeit
- Operations & Supply Chain: Lagerbestands-Prognosen, Optimierung von Logistikrouten
4. Context Engineering für LLMs
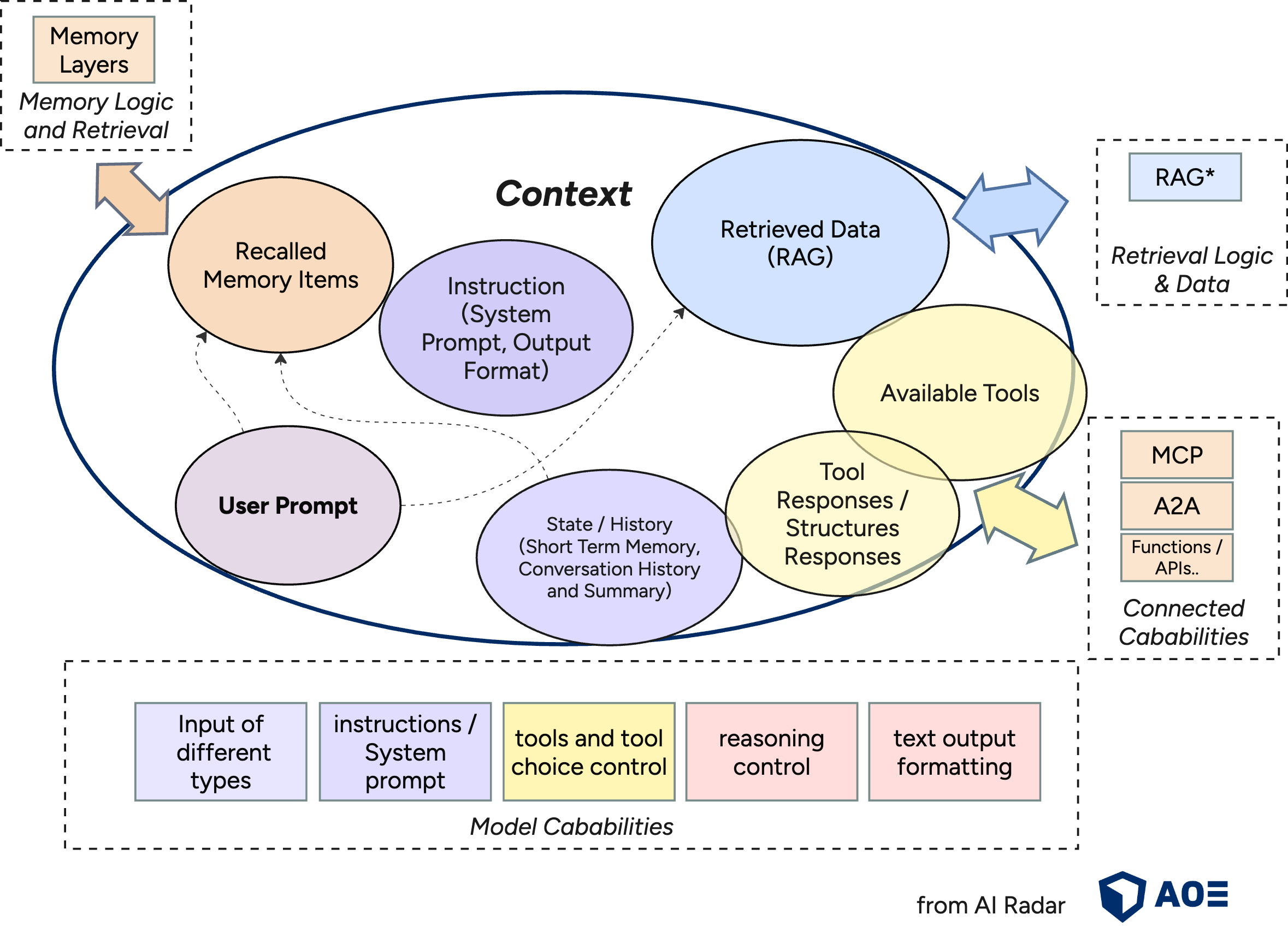
Kennst du diese LinkedIn-Posts, in denen sich Leute über lustige, aber unbrauchbare ChatGPT-Antworten aufregen, und dann kommt immer eine(r) in den Kommentaren mit „das liegt daran, dass du keinen Kontext gegeben hast…“? Das kannst du als einfachste (und oft fehlgeschlagene) Version von Context Engineering sehen. Im Kern geht es darum, zu entscheiden, welche Informationen in das begrenzte Kontextfenster (= die maximale Menge an Tokens, die ein LLM gleichzeitig verarbeiten kann) eines Modells passen und wie du diese strukturierst, damit du zuverlässig das gewünschte Ergebnis bekommst.
Erfolgreiches Arbeiten mit LLMs bedeutet in der Praxis, den Kontext als die vollständige Menge an Informationen zu betrachten, die dem Modell jederzeit zur Verfügung steht (dazu zählen Systemanweisungen, Gesprächsverlauf, abgerufene Dokumente, Nutzerdaten, Tool-Outputs und so weiter), und die daraus resultierenden Verhaltensweisen einzuschätzen.
Was ist der Unterschied zwischen Prompt Engineering und Context Engineering?
Der Trend Context Engineering stellt einen weiterentwickelten Ansatz dar, der das volle Spektrum dessen betrachtet, was „Kontext“ bedeuten kann. Zunächst sollten wir jedoch klären, was Context Engineering genau ist und wie es sich vom Prompt Engineering unterscheidet, das in den letzten Jahren die Diskussionen über KI dominiert hat: Beim Prompt Engineering geht es darum, Anweisungen zu formulieren, während Context Engineering das gesamte Input-Ökosystem gestaltet. Anders gesagt: Ein Prompt ist nur ein Teil des Kontexts. Eine detaillierte Gegenüberstellung von Prompt und Context Engineering findest du übrigens in diesem Artikel von Anthropic.
Welche Vorteile hat Context Engineering für LLMs?
Ziel des Context Engineerings ist es, die Relevanz der Ausgaben innerhalb begrenzter Kontextfenster zu maximieren, gleichzeitig die Latenz zu minimieren und eine hohe Zuverlässigkeit zu gewährleisten. Das bedeutet, dass gutes Context Engineering direkte Auswirkungen auf Kosten, Leistung und Zuverlässigkeit von KI-Systemen haben kann. Context Engineering optimiert die gesamte Informationslandschaft, auf die ein LLM während der Inferenz zugreifen kann: Prompts, Memory, abgerufene Daten, aktueller Gesprächszustand und Tool-Outputs. Dabei kommen verschiedene Techniken zum Einsatz, wie z. B. Chunking, Retrieval-Routing, Memory-Management oder strukturierte API-Aufrufe. Letztendlich geht es darum, Systeme so zu gestalten, dass ein LLM genau die Informationen und Werkzeuge erhält, die es benötigt – richtig strukturiert und zum richtigen Zeitpunkt –, um eine Aufgabe erfolgreich zu erfüllen.
Was ein LLM erzeugt, wird in erster Linie vom Kontext bestimmt, den es erhält, also von den bereitgestellten Informationen, deren Struktur und ihrer relativen Bedeutung. In realen agentischen Systemen oder RAG-Pipelines unterstützt gutes Context Engineering entscheidend dabei, experimentelle Prototypen in skalierbare Systeme zu verwandeln.
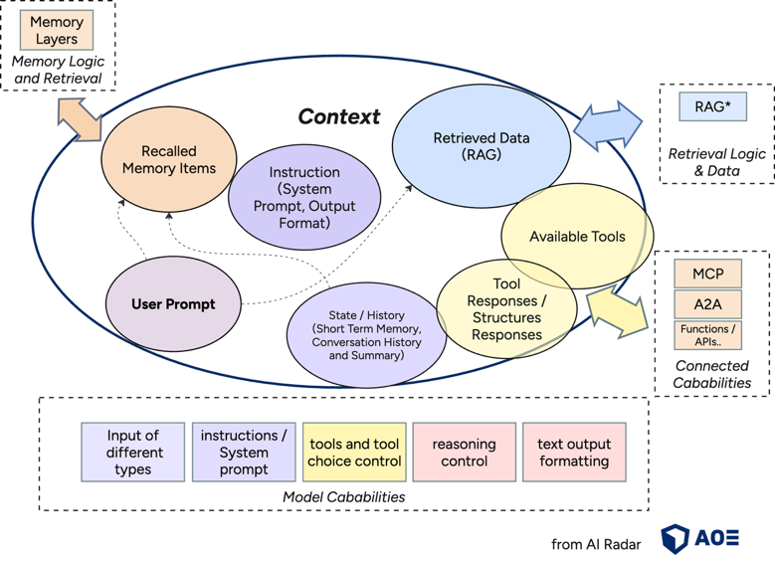
Quelle der Grafik: AOE AI Radar (https://ai-radar.aoe.com/images/context-engineering.png)
{kind=link}
5. Generierung synthetischer Daten (SDG)
Für ein effektives Modelltraining benötigt man eine ausreichende Menge an Daten. Oft sogar gigantische Mengen. Aber was passiert, wenn nicht genügend qualitativ hochwertige Daten verfügbar sind? Hier kommen synthetische Daten ins Spiel. Synthetische Daten sind künstlich erzeugte Daten, die viele Formen annehmen können: Texte, Bilder, Videos, tabellarische Daten und mehr; sowohl strukturiert als auch unstrukturiert. Sie werden mithilfe von Regeln, Algorithmen oder Simulationen erstellt, die die statistischen Eigenschaften realer Daten nachahmen. Dadurch können sie sich gut zum Trainieren, Validieren und Testen von Modellen eignen.
Wie werden synthetische Daten erzeugt?
Synthetische Daten lassen sich über Computersimulationen, mathematische Modelle oder generative KI-Systeme erzeugen. Beispielsweise ist NVIDIAs Nemotron‑4 340B eine Familie generativer Modelle, mit denen Entwickler synthetische, textbasierte Daten für das Training von LLMs erstellen können. Ebenso können Methoden wie GANs (Generative Adversarial Networks) realistische Bilder erzeugen, während Simulationssoftware synthetische Sensordaten oder IoT-Daten für autonome Fahrzeuge erstellen kann. Der Erstellungsprozess kann gezielt gesteuert werden, um ausgewogene, vielfältige und realistische Datensätze zu erzeugen, die die Eigenschaften realer Daten widerspiegeln, während gleichzeitig das Risiko verringert wird, sensible Informationen zu kopieren oder preiszugeben.
Wann ist die Generierung synthetischer Daten (SDG) sinnvoll?
Synthetische Daten sind in vielen Bereichen nützlich. Insbesondere dann, wenn reale Daten:
- Begrenzt sind (Datenknappheit)
→ Beispielsweise sind medizinische Bilddatensätze für seltene Krankheiten oft zu klein, um effektive KI-Modelle zu trainieren. Synthetische Bilder können diese Datensätze ergänzen. - Unausgewogen oder nicht repräsentativ sind
→ Das Training von Modellen auf Datensätzen mit verzerrten Klassenverteilungen kann zu voreingenommenen Ergebnissen führen. Synthetische Daten können Lücken füllen, z. B. durch die Erstellung zusätzlicher Beispiele für unterrepräsentierte Kategorien in Kreditrisikodatensätzen. - Aufgrund ihrer Sensitivität schwer nutzbar sind
→ Bestimmte Daten, wie Finanztransaktionen, Rechtsakten oder Patientendaten, unterliegen strengen Datenschutz- und Sicherheitsanforderungen. Synthetische Daten können Muster aus diesen Datensätzen nachbilden, ohne persönliche Informationen preiszugeben, und sind somit sicher für Training und Weitergabe.
In solchen Fällen ermöglicht die Generierung und Nutzung synthetischer Daten, qualitativ hochwertige und vielfältige Datensätze zu erstellen, die die Modellleistung verbessern, die Zeit zur Beschaffung realer Daten verkürzen und den KI-Entwicklungsprozess beschleunigen.
Generierung synthetischer Daten (SDG) für Evaluation-Driven Development (EDD)
Synthetische Daten sind außerdem besonders hilfreich für das zuvor erwähnte Evaluation-Driven Development (EDD): Sie können als kontrollierte, hochwertige Evaluationsdatensätze dienen, um die Modellleistung unter verschiedenen Szenarien zu testen, Schwächen zu identifizieren und auf Basis der gewonnenen Erkenntnisse schnell zu iterieren. Beispielsweise kann ein synthetischer Datensatz für den Kundenservice genutzt werden, um zu prüfen, wie ein KI-Chatbot seltene oder komplexe Anfragen behandelt, ohne echte Kundengespräche preiszugeben.
Abschließende Gedanken zu unseren 5 Data- & AI-Engineering-Trends in 2026
Wir haben dir unsere 5 Data- & AI-Engineering-Trends für 2026 vorgestellt: multimodale Lakehouses, Evaluation-Driven Development (EDD), KI-native Datenplattformen, Context Engineering für LLMs und die Generierung synthetischer Daten (SDG). Je weiter sich die Technologien entwickeln, desto schwieriger wird es, sich auf ein paar wenige zu konzentrieren, um Projekte und Produkte wirklich voranzubringen, ohne sich in den ganzen spannenden Möglichkeiten zu verlieren. Reflektiere also gerne noch einmal kritisch: Welche dieser Trends sind für dich nice to have oder erscheinen dir so spannend, dass du sie bald integrieren möchtest? Und welche hältst du tatsächlich für langfristig relevant und unverzichtbar…?
Author info
